Il World
Wide Web (WWW, o semplicemente Web) è uno spazio informativo
nel quale gli elementi d'interesse, a cui ci si riferisce come risorse,
sono individuate da identificatori globali chiamati Identificatori Uniformi
di Risorsa {Uniform Resource Identifiers} (URI).
Esempi come il seguente scenario di viaggio sono utilizzati attraverso tutto
questo documento per illustrare il tipico comportamento degli agenti Web — persone o software
che agiscono in questo spazio informativo. Un agente utente {user agent} agisce comportandosi come un utente. Gli agenti software
includono server, proxy, spider, browser e riproduttori multimediali.
Aneddoto
Mentre organizza un viaggio in Messico, Nadia
legge “Informazione meteorologica per Oaxaca: 'http://weather.example.com/oaxaca'”
in una rivista di viaggi patinata. Nadia ha abbastanza esperienza con
il Web per riconoscere il fatto che "http://weather.example.com/oaxaca" è un
URI e che ella è in grado di recuperare l'informazione associata
con il suo browser Web. Quando Nadia inserisce l'URI nel suo browser:
- Il browser riconosce ciò che Nadia ha digitato come un URI.
- Il browser compie un'azione di reperimento dell'informazione in accordo
con il suo comportamento configurato per risorse identificate attraverso
lo schema URI di "http".
- L'autorità responsabile di "weather.example.com" fornisce
informazione in una risposta alla richiesta di reperimento.
- Il browser interpreta la risposta, identificata come XHTML dal server,
e compie azioni di reperimento aggiuntive per la grafica inglobata
e altro contenuto come necessario.
- Il browser mostra a video l'informazione reperita, la quale include
collegamenti ipertestuali ad altre informazioni. Nadia può seguire
questi collegamenti ipertestuali per reperire le informazioni aggiuntive.
Questo scenario illustra le tre basi architetturali
del Web che sono discusse in questo documento:
-
Identificazione (§2). Gli URI sono usati per identificare risorse.
In questo scenario del viaggio, la risorsa è un rapporto periodicamente aggiornato sul tempo a Oaxaca, e l'URI
è “http://weather.example.com/oaxaca”.
-
Interazione (§3). Gli agenti Web
comunicano usando protocolli standardizzati che abilitano l'interazione
attraverso lo scambio di messaggi i quali aderiscono a una sintassi e ad
una semantica definite. Inserendo un URI all'interno di una maschera di reperimento o selezionando
un collegamento ipertestuale, Nadia dice al proprio browser di compiere
un'azione di reperimento per la risorsa identificata dall'URI. In questo
esempio, il browser invia una richiesta GET tramite HTTP (una parte del
protocollo HTTP) al server presso "weather.example.com", tramite la porta
80 di TCP/IP, e il server rimanda un messaggio contenente ciò che esso
decide essere una rappresentazione della risorsa nel momento in cui quella
rappresentazione è stata generata. Si noti che questo esempio è peculiare
della navigazione ipertestuale delle informazioni — sono possibili altri
tipi di interazioni, tutte all'interno dei browser e attraverso l'impiego
di altri tipi di agenti Web; il nostro esempio è inteso a illustrare una
singola comune interazione, non a definire il campo delle possibili
interazioni o limitare i modi in cui gli agenti potrebbero utilizzare il
Web.
-
Formati (§4). La maggior parte dei protocolli usati per il
reperimento e/o la richiesta di rappresentazione fanno uso di una sequenza
di uno o più messaggi, che presi nel loro insieme contengono un carico
di dati e metadati della rappresentazione, per trasferire la
rappresentazione fra gli agenti. La scelta di un protocollo per
l'interazione pone dei limiti ai formati dei dati e dei metadati della
rappresentazione che possono essere trasmessi. L'HTTP, per esempio,
tipicamente trasmette un singolo flusso di ottetto {octet stream} più i
metadati, e utilizza i campi delle intestazioni "Content-Type" e "Content-Encoding"
per identificare più avanti il formato della rappresentazione. In questo
scenario, la rappresentazione trasferita è in XHTML, così come
identificata dal campo d'intestazione HTTP "Content-type" contenente il
nome del tipo registrato di media per Internet, "application/xhtml+xml".
Quel nome di tipo di media per Internet indica che i dati della
rappresentazione possono essere processati in accordo alla specifica XHTML.
Il browser di Nadia è configurato e programmato
per interpretare la ricezione di una rappresentazione di tipo "application/xhtml+xml"
come un'istruzione per rendere il contenuto di quella rappresentazione in
accordo con il modello di presentazione XHTML, incluse ogni interazioni
sussidiarie (come le richieste di fogli di stile esterni o di immagini
incorporate) richiamate dalla rappresentazione. Nello scenario, i dati
della rappresentazione XHTML ricevuti dalla richiesta iniziale istruisce
il browser di Nadia anche a reperire e rendere le mappe meteorologiche
incorporate, ognuna identificata da un URI e causando in questo modo
un'azione di reperimento aggiuntiva, la quale si risolve in
rappresentazioni aggiuntive che vengono processate dal browser in accordo
ai propri formati di dati
(ad es., "application/svg+xml" indicate il formato di dati SVG), e
questo processo continua fino a quando tutti i formati dei dati siano
stati presentati. Il risultato di tutto questo procedimento, una volta che
il browser ha raggiunto uno stato
di quiete
dell'applicazione che completa l'azione iniziale richiesta da Nadia, è ciò
a cui ci si riferisce comunemente come una "pagina Web".
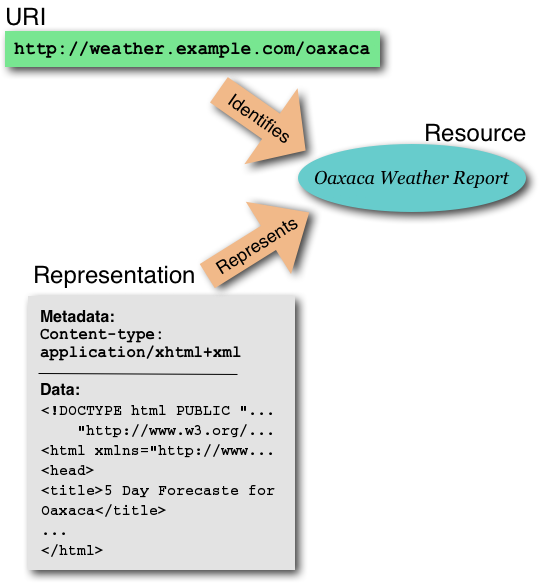
L'illustrazione seguente mostra la relazione fra
identificatore, risorsa e rappresentazione.
Nel prosieguo di questo documento. evidenzieremo
importanti punti architetturali riguardanti identificatori, protocolli e
formati del Web. Tratteremo inoltre alcuni importanti
principi generali di architettura (§5) e di come questi si
applichino al Web.
Questo documento descrive le proprietà che
desideriamo per il Web e le scelte di progettazione che sono state fatte per
conseguirle.
Esso promuove il riutilizzo degli standard esistenti quando adattabili e
fornisce una guida su come innovare in maniera consistente con
l'architettura del Web.
I termini DEVE, NON DEVE, DOVREBBE, NON DOVREBBE e
POTREBBE sono impiegati nei principi, nei vincoli e nelle note di buona
prassi in conformità alla RFC 2119 [RFC2119].
Questo documento non include condizioni di
conformità per queste ragioni:
- Si prefigura che il software conforme sia così vario che non sarebbe
di giovamento essere in grado di riferirsi alla categoria degli agenti di
software conforme.
- Qualcuna delle note di buona prassi riguardano persone; le specifiche,
generalmente, definiscono la conformità per il software, non per le
persone.
- Non crediamo che l'aggiunta di una sezione per la conformità porti
verosimilmente a incrementare l'utilità del documento.
Questo documento è stato pensato per alimentare
i dibattiti riguardo le questioni dell'architettura del Web. Il pubblico
di riferimento per questo documento include:
- Partecipanti alle Attività del W3C
- Altri gruppi e singoli che progettano tecnologie da integrarsi nel Web
- Implementatori delle specifiche del W3C
- Autori ed editori di contenuti Web
Note: Questo documento non fa
distinzione in alcun modo formale fra i termini "linguaggio" e "formato."
Il contesto
determina quale termine viene usato. La frase "progettista di specifica"
ricomprende progettisti di linguaggio, di formato e di protocollo.
Questo documento presenta l'architettura
generale del Web. Anche altri gruppi all'interno e fuori del W3C
indirizzano aspetti specifici dell'architettura Web, inclusi
accessibilità, garanzia di qualità,
internazionalizzazione, indipendenza dal dispositivo e Web Service. La
sezione sulle Specifiche Architetturali (§7.1) include riferimenti a queste
specifiche correlate.
Questo documento si sforza di bilanciare
concisione e accuratezza al contempo includendo esempi illustrativi.
Le conclusioni del TAG
sono documenti informativi che sono complementari al presente documento
fornendo maggior dettaglio riguardo gli argomenti discussi. Questo
documento include alcune citazioni delle conclusioni. Dal momento che le
conclusioni evolvono indipendentemente, questo documento include
riferimenti alle conclusioni del TAG. Per altre questioni del TAG coperte
da questo documento, ma prive di una conclusione approvata, i riferimenti
sono alle voci nell'Elenco di questioni del
TAG.
Molti degli esempi in questo documento che
coinvolgono attività umana presuppongono il modello conosciuto di
interazione del Web (illustrato all'inizio dell'Introduzione) dove una
persona segue un collegamento per il tramite di un agente utente, l'utente
agente reperisce e presenta i dati, l'utente segue un altro collegamento,
etc. Questo documento non discute in nessun aspetto altri modelli di
interazione, come la navigazione vocale (vedi, per esempio, [VOICEXML2]). La scelta del modello di interazione potrebbe avere
un impatto sul comportamento atteso dagli agenti. Per esempio, quando un
agente utente grafico che gira su un computer portatile o su un dispositivo
palmare s'imbatte in un errore, l'agente utente può riportare gli errori
direttamente all'utente attraverso suggerimenti visivi e uditivi e
presenta all'utente delle opzioni per risolvere gli errori. D'altro canto,
quando qualcuno sta navigando nel Web
attraverso input vocale e output esclusivamente audio, bloccare la
maschera di immissione in attesa
dell'input dell'utente potrebbe ridurre l'usabilità poiché è molto facile
"perdere la bussola" quando si naviga solo con l'output audio. Questo
documento non discute del come principi, vincoli e buone prassi qui
identificate si applichino in tutti contesti d'interazione.
I punti importanti del presente documento
sono riuniti in categorie nel modo che segue:
- Principio
- Un principio architetturale è una regola fondamentale che si applica
ad un vasto numero di situazioni e variabili. I principi architetturali
includono "separazione degli aspetti", "interfaccia generica", "sintassi
auto-descrittiva", "semantica visibile", "effetto di rete" (Legge di
Metcalfe), e la Legge di Amdahl: "La velocità di un sistema è limitata
dal suo componente più lento".
- Vincolo
- Nella progettazione del Web, alcune scelte, come i nomi degli
elementi
p e li
in HTML, la scelta del carattere dei due punti (:) negli URI o
raggruppare i bit in unità di otto bit (ottetti), sono qualcosa di
arbitrario; se paragraph fosse stato scelto al posto di
p o l'asterisco (*) al posto dei due punti, il risultato su
vasta scala sarebbe stato, molto probabilmente, lo stesso. Questo
documento si focalizza su scelte di progettazione più fondamentali:
scelte di progettazione che hanno condotto ai vincoli, ovvero
restrizioni nel comportamento o nell'interazione all'interno del
sistema. I vincoli potrebbero essere imposti per ragioni tecniche,
politiche o altre per conseguire proprietà preferenziali nel sistema,
come l'accessibilità, l'ambito globale, relativa facilità di evoluzione,
efficienza ed estensibilità dinamica.
- Buona prassi
- La buona prassi — da parte degli sviluppatori software, degli autori
di contenuti, dei gestori di siti, degli utenti e dei progettisti di
specifiche — incrementa il valore del Web.
Nell'ottica di comunicare internamente, una comunità
concorda (in maniera ragionevole) su un insieme di termini e sui loro
significati. Un obiettivo del Web, sin dal suo principio, è stato costruire
una comunità globale nella quale ciascuna parte può dividere informazioni con
qualunque altra parte. Per raggiungere questo obiettivo, il Web fa uso di un
singolo sistema di identificazione globale: l'URI. Gli URI sono la chiave di
volta dell'architettura Web, fornendo l'identificazione che è comune per tutto
il Web. L'ambito globale degli URI promuove "effetti di rete" su vasta scala:
il valore di un identificatore cresce maggiormente quando è impiegato in
maniera consistente (per esempio, maggiormente quando è usato nei
collegamenti ipertestuali (§4.4)).
Principio: Identificatori
Globali
Assegnare nomi globali conduce a
effetti di rete globali.
Questo principio risale almeno fino al lavoro
fondamentale di Douglas
Engelbart sui sistemi ipertestuali aperti; si veda la sezione
Ogni
Oggetto Indirizzabile in [Eng90].
La scelta di una sintassi per gli identificatori
globali è qualcosa di arbitrario; è il loro scopo globale ad essere
importante. L' Identificatore Uniforme di Risorsa, {Uniform
Resource Identifier} [URI], è stato impiegato con successo sin dalla creazione
del Web. Esistono benefici sostanziali nel partecipare alla rete esistente
di URI, fra questi i collegamenti, i bookmark, la cache e l'indicizzazione
da parte dei motori di ricerca, ed esistono costi non indifferenti nel
creare un nuovo sistema di identificazione che abbia le stesse proprietà
degli URI.
Buona prassi: Identificare con gli URI
Per beneficiare del valore del World Wide Web
e per incrementarlo, gli agenti dovrebbero fornire URI come identificatori
per le risorse.
Una risorsa dovrebbe avere un URI associato se
un'altra parte potrebbe ragionevolmente voler creare un collegamento
ipertestuale ad esso; fare o rifiutare asserzioni al loro riguardo, reperire
o mettere in cache una rappresentazione di essa, includerla tutta o in parte
attraverso un riferimento a un'altra rappresentazione, annotarla o compiere
altre operazioni su di essa. Gli sviluppatori del software dovrebbero
aspettarsi che condividere gli URI tra le varie applicazioni sarà di grande
utilità, perfino se questa stessa utilità non sia evidente fin da subito. La
conclusione del TAG "URI,
Indirizzabilità e l'uso di GET e POST in HTTP" tratta dei
benefici aggiuntivi e delle considerazioni sull'indirizzabilità dell'URI.
Note: Alcuni schemi di URI (come
la specifica per lo schema URI di "ftp") usano il termine "designare" dove
questo documento usa "identificare".
Per definizione un URI identifica una sola risorsa.
Non limitiamo l'ambito di cosa potrebbe essere una risorsa. Il termine "risorsa" è impiegato in un
senso generale per qualunque cosa possa essere identificata da un URI. È
convenzionale nel Web ipertestuale descrivere pagine Web, immagini,
cataloghi di prodotti, etc. come "risorse". Il carattere peculiare di queste
risorse è che tutte le loro caratteristiche essenziali possono essere
convogliate in un messaggio. Identifichiamo questo insieme come “risorse informative”.
Questo documento è un esempio di una risorsa
informativa.
Esso consiste in parole e simboli d'interpunzione e grafica e altri
artefatti che possono essere codificati, con vari gradi di fedeltà, in una
sequenza di bit. Non esiste nulla rispetto all'informazione essenziale
contenuto di questo documento che non può in principio essere trasferito in
un messaggio. Nel caso del presente documento, il messaggio in carico è la rappresentazione di questo documento.
Comunque, il nostro uso del termine risorsa è
intenzionalmente più esteso. Anche altre cose, come le automobili e i cani
(e, se avete stampato questo documento su fogli di carta fisici, l'artefatto
che state tenendo nelle vostre mani), sono risorse. Non sono risorse
informative, in ogni caso, perché la loro essenza non è l'informazione.
Sebbene sia possibile descrivere un gran numero di cose riguardo a
un'automobile o a un cane in una sequenza di bit, la somma di quelle cose
sarà invariabilmente un'approssimazione del carattere essenziale della
risorsa.
Definiamo il termine “risorsa informativa” perché
osserviamo che è utile nelle discussioni sulla tecnologia Web e potrebbe
essere utile nel costruire specifiche per strutture adibite all'uso sul Web.
Vincolo: gli URI Identificano una Singola Risorsa
Assegnare URI differenti a
risorse differenti.
Dal momento che l'ambito di un URI è globale, la
risorsa identificata da un URI non dipende dal contesto nel quale gli URI
compaiono (si veda anche la sezione sulle identificazioni indirette (§2.2.3)).
[URI] è un accordo riguardo al come la comunità Internet allochi i
nomi e al come li associ alle risorse che essi identificano. Gli URI sono
divisi in schemi (§2.4) che definiscono, per il tramite della loro
specifica di schema, il meccanismo per il quale identificatori di schemi
specifici sono associati con le risorse. Per esempio, lo schema URI per
"http" ([RFC2616]) usa server HTTP DNS e basati su TCP con il proposito
dell'allocazione e la risoluzione dell'identificatore. Come risultato,
identificatori come "http://example.com/somepath#someFrag" spesso assumono
significato attraverso l'esperienza della comunità nel compiere una
richiesta GET in HTTP sull'identificatore e, se fornito un responso
positivo, interpretando il responso come una rappresentazione della risorsa
identificata. (Si veda anche Identificatori di Frammento (§2.6).) Naturalmente, un'azione di
reperimento come GET non è l'unico modo per ottenere informazione in merito
ad una risorsa. Si potrebbe anche pubblicare un documento che abbia la
pretesa di definire il significato di un particolare URI. Queste altre fonti
di informazione potrebbero suggerire significati per tali identificatori, ma
è una decisione dettata da una condotta locale, se si dovesse dar retta a
quei suggerimenti.
Proprio come qualcuno potrebbe voler riferirsi ad
una persona con nomi differenti (per nome e cognome, solo per cognome, per
soprannome sportivo o affettuoso, e così via), l'architettura Web permette
l'associazione di più di un unico URI con una risorsa. Gli URI che
identificano la stessa risorsa sono chiamati
alias di URI. La sezione
sugli alias di URI (§2.3.1) tratta alcuni dei costi potenziali nel
creare molteplici URI per la stessa risorsa.
Alcune sezioni di questo documento pongono domande
circa la relazione fra URI e risorse, tra cui:
Per definizione, un URI identifica una sola
risorsa. L'utilizzo dello stesso URI per identificare direttamente risorse
differenti produce una collisione di URI. La
collisione spesso impone un costo nella comunicazione dovuto allo sforzo
richiesto per risolvere le ambiguità.
Supponiamo, per esempio, che un'organizzazione
faccia uso di un URI per riferirsi al film La Stangata e
un'altra organizzazione utilizzi il medesimo URI per riferirsi ad un forum
di discussione su La Stangata. Per una terza parte, a
conoscenza di entrambe le organizzazioni, questa collisione crea
confusione riguardo a cosa identifichi l'URI, sminuendo il
valore dell'URI. Se uno volesse parlare della data di creazione della
risorsa identificata dall'URI, per esempio, non sarebbe chiaro se questo
significhi "quando il film è stato creato" o "quando il forum di
discussione sul film è stato creato".
Sono state escogitate soluzioni sociali e
tecniche per aiutare ad evitare la collisione di URI. Comunque, il
successo o il fallimento di questi differenti approcci dipende
dall'estensione del consenso nella comunità di Internet sul
tollerare le specifiche che li definiscono.
La sezione sull'allocazione di URI (§2.2.2) esamina gli approcci per stabilire la
fonte autoritativa dell'informazione riguardo a cosa un URI voglia
identificare.
Gli URI talvolta sono impiegati per l'identificazione indiretta (§2.2.3). Questa non porta
necessariamente a delle collisioni.
L'allocazione di URI è il processo di
associazione fra un URI e una risorsa. L'allocazione può essere conseguita
sia dai proprietari della risorsa che da terzi. È importante evitare la
collisione di URI (§2.2.1).
La
proprietà dell'URI è una relazione fra
un URI e un'entità sociale, come una persona, un'organizzazione o una
specifica.
La proprietà dell'URI dà alla relativa entità sociale certi
diritti, fra i quali:
- trasferire la proprietà della totalità o di parte degli URI
posseduti a un altro proprietario — delega;
e
- associare una risorsa a un URI di proprietà — allocazione di URI.
Per convenzione sociale, la proprietà dell'URI
è delegata dal registro degli schemi di URI della IANA [IANASchemes], essa stessa un'entità sociale, alle specifiche dello
schema di URI dei soggetti registrati alla IANA. Alcune specifiche dello schema
di URI più avanti delegano la proprietà a registri subordinati o ad
altri proprietari ufficiali designati, che potrebbero più avanti delegare la proprietà. Nel caso di una specifica, la
proprietà in ultima istanza risiede nella comunità che si occupa della
specifica.
L'approccio preso per lo schema URI di "http",
per esempio, segue il percorso per mezzo di cui la comunità di Internet delega
l'autorità, per il tramite del registro di schema URI della IANA e
del DNS, a un insieme di URI con un prefisso comune a uno specifico
proprietario. Una conseguenza di questo approccio è il pesante
affidamento del Web al registro centralizzato del DNS.
Un approccio differente è preso dallo schema di Sintassi URN [RFC2141] il quale delega la proprietà di porzioni di spazi URN
alle specifiche di Namespace URN, registrate esse stesse in un registro
a cura della IANA di Identificatori del Namespace URN.
I proprietari di URI hanno la responsabilità
di evitare l'assegnazione di URI equivalenti a risorse multiple. In
questo modo, se una specifica di schema URI supporta la delega di URI,
singoli o in insiemi organizzati, dovrebbe avere a cuore di assicurare che la proprietà in ultima istanza risieda nelle mani di
una singola entità sociale. Consentire molteplici proprietari incrementa
la probabilità delle collisioni URI.
I proprietari di URI potrebbero organizzare o
impiegare un'infrastruttura per garantire che le
rappresentazioni delle risorse associate siano disponibili e, dove
appropriato, che sia possibile l'interazione con la risorsa attraverso
lo scambio di rappresentazioni. Esistono aspettative sociali per una
gestione della rappresentazione (§3.5) responsabile da parte dei
proprietari di URI. Qui non vengono trattate ulteriori implicazioni
sociali della proprietà dell'URI.
Si veda la questione del TAG
siteData-36, che riguarda l'espropriazione dell'autorità di
assegnare i nomi {naming}.
2.2.2.2. Altri schemi di allocazione
Alcuni schemi usano tecniche diverse da quelle
della proprietà delegata per evitare la collisione. Per esempio, la
specifica per gli schemi dei dati URL (sic) [RFC2397] specifica che la risorsa identificata da un URI di
schema di dati ha una sola possibile rappresentazione. I dati della
rappresentazione preparano l'URI che identifica quella risorsa. Così, la
specifica stessa determina come vengono allocati gli URI dei dati; la
delega non è possibile.
Altri schemi (come "news:comp.text.xml")
si basano su di un processo sociale.
Affermare che l'URI "mailto:nadia@example.com" identifica
sia una casella di posta Internet che Nadia, la persona, introduce una
collisione di URI.
In ogni caso, possiamo usare l'URI per identificare indirettamente
Nadia. Gli identificatori sono comunemente impiegati in questo modo.
Ascoltando un notiziario, si potrebbe sentire
un servizio dalla Gran Bretagna che inizia, "Oggi, il 10 di Downing Street
ha annunciato una serie di nuove misure economiche". In genere, "il 10 di
Downing Street" identifica la residenza ufficiale del Primo Ministro
britannico. In questo contesto, l'annunciatore sta usando (siccome glielo
consente la retorica dell'inglese) di identificare indirettamente il
governo britannico. In maniera similare, gli URI identificano risorse, ma
a loro volta possono anche essere impiegati in molti costrutti per
identificare indirettamente altre risorse. Politiche di assegnazione
adottate in modo globale rendono alcuni URI interessanti come
identificatori a scopo generico. Una politica locale stabilisce a cosa
essi si riferiscono indirettamente.
Supponiamo che nadia@example.com
sia l'indirizzo di posta elettronica di
Nadia. Gli organizzatori di una conferenza a cui Nadia partecipa
potrebbero usare "mailto:nadia@example.com" per riferirsi indirettamente a
lei (ovvero, impiegando l'URI come una chiave di database nel loro
archivio dei partecipanti alla conferenza).
Questo non introduce una collisione di URI.
Gli URI che sono identici, carattere per
carattere, si riferiscono alla stessa risorsa. Poiché l'Architettura Web
permette l'associazione di molteplici URI con una data risorsa, due URI che
non sono identici alla lettera potrebbero ancora riferirsi alla stessa
risorsa. URI differenti non necessariamente si riferiscono a risorse
differenti, ma in genere c'è un elevato costo computazionale nel determinare
che URI differenti si riferiscono alla stessa risorsa.
Per ridurre il rischio di un falso negativo (cioè,
una conclusione errata che due URI non si riferiscono alla stessa risorsa) o
un falso positivo (cioè, una conclusione errata che due URI si riferiscono
alla stessa risorsa), alcune specifiche descrivono test di equivalenza in
aggiunta alla comparazione carattere per carattere. Gli agenti che traggono
conclusioni basate su comparazioni non autorizzate dalle relative
specifiche si assumono la responsabilità per qualsiasi problema che ne
derivi; si veda la sezione sulla
gestione dell'errore (§5.3) per maggiori informazioni riguardo il
comportamento responsabile quando si traggono conclusioni non autorizzate.
La sezione 6 di [URI] fornisce maggiori informazioni riguardo la comparazione
degli URI e la riduzione del rischio di falsi negativi e falsi positivi.
Si veda anche l'affermazione che due URI identificano la stessa risorsa (§2.7.2).
Sebbene esistano benefici (come la flessibilità
nell'assegnare i nomi {naming}) per gli alias dell'URI, esistono anche dei costi. Gli alias di
URI sono dannosi quando dividono il Web delle risorse
correlate. Un corollario del Principio di Metcalfe (l'"effetto di rete") è
che il valore di una data risorsa può essere misurata dal numero e dal
valore di altre risorse nelle vicinanze della propria rete, sarebbe a
dire, le risorse che si collegano ad essa.
Il problema con gli alias è che se metà del
vicinato punta per una data risorsa a un primo URI e l'altra metà punta a
un secondo URI differente per la stessa risorsa, il vicinato viene diviso. Non
solo la risorsa con l'alias viene sottostimata a causa di questa
separazione, ma tutte le risorse delle vicinanze perdono valore a causa delle
relazioni mancanti di second'ordine che sarebbero dovute esistere tra le
risorse di riferimento in virtù dei loro riferimenti alla risorsa con
alias.
Buona prassi:
Evitare gli alias dell'URI
Un proprietario di URI NON
DOVREBBE associare URI arbitrariamente differenti con la stessa risorsa.
Anche chi usufruisce degli URI gioca un ruolo nel
garantire la consistenza dell'URI. Per esempio, nel momento in cui
trascrivono un URI, gli agenti non dovrebbero operare gratuitamente la
codifica percentuale dei caratteri. Il termine "carattere" si riferisce ai
caratteri di URI definiti nella sezione 2 di [URI]; la codifica percentuale viene trattata nella sezione 2.1 di
quella specifica.
Buona prassi:
Utilizzo consistente dell'URI
Un agente che riceve un URI
DOVREBBE riferirsi alla risorsa associata impiegando lo stesso URI,
carattere per carattere.
Quando un alias di URI diventa di uso comune, il
proprietario dell'URI dovrebbe usare delle tecniche protocollari
come i reindirizzamenti lato server per mettere in relazione le due risorse.
La comunità trae beneficio dal fatto che il proprietario dell'URI supporta
il reindirizzamento di un URI con alias al corrispondente URI "ufficiale".
Per altre informazioni sul reindirizzamento, si veda la sezione 10.3,
Reindirizzamento, nella
[RFC2616]. Si veda anche [CHIPS] per una trattazione di alcune delle prassi migliori per
gli amministratori di server.
Dare un alias all'URI è un'operazione che
ricorre solo quando più di un URI viene usato per identificare la stessa
risorsa. Il fatto che risorse differenti a volte abbiano la stessa
rappresentazione non fa di quegli URI degli alias per quelle risorse.
Aneddoto
Dirk vorrebbe aggiungere un collegamento dal
suo sito Web a quello meteorologico di Oaxaca. Egli utilizza l'URI http://weather.example.com/oaxaca
ed etichetta il suo collegamento “bollettino meteorologico di Oaxaca
del 1° agosto 2004”.
Nadia fa notare a Dirk che sta fornendo delle aspettative svianti
per l'URI che ha utilizzato. La linea di condotta del sito
meteorologico di Oaxaca è che l'URI in questione identifica un
bollettino del tempo attuale di Oaxaca — in un dato giorno qualsiasi —
e non il tempo del 1° agosto. Naturalmente, il primo d'agosto del
2004, il collegamento di Dirk sarà corretto, ma per il resto dei
giorni egli svierà i lettori. Nadia fa notare a Dirk che i gestori del
sito meteorologico di Oaxaca mettono a disposizione un URI diverso
assegnato permanentemente alla risorsa che fa rapporto sul tempo
meteorologico il 1° agosto 2004.
In questo aneddoto, ci sono due risorse: "un
bollettino meteorologico di Oaxaca attuale" e "un bollettino meteorologico
di Oaxaca del 1° agosto 2004". I gestori del sito meteorologico di Oaxaca
assegnano due URI per quelle due differenti risorse. Il 1° agosto 2004, le
rappresentazioni per quelle risorse sono identiche. Il fatto che seguire i
riferimenti di due URI differenti produca rappresentazioni identiche non
implica che i due URI siano degli alias.
Nell'URI "http://weather.example.com/", l'"http"
che appare prima dei due punti (":") designa uno schema di URI.
Ogni schema di URI ha una specifica che spiega i suoi dettagli peculiari di
come gli identificatori di schema sono allocati e vengono associati a una
risorsa. La sintassi dell'URI è in questo modo un sistema di
assegnazione dei nomi {naming} federato
ed estensibile in cui ogni specifica dello schema potrebbe successivamente
restringere la sintassi e la semantica degli identificatori all'interno di
quello schema.
Esempi di URI da vari schemi includono:
- mailto:joe@example.org
- ftp://example.org/aDirectory/aFile
- news:comp.infosystems.www
- tel:+1-816-555-1212
- ldap://ldap.example.org/c=GB?objectClass?one
- urn:oasis:names:tc:entity:xmlns:xml:catalog
Sebbene l'architettura Web permetta la definizione
di nuovi schemi, introdurre un nuovo schema è dispendioso. Molti aspetti
dell'elaborazione dell'URI sono dipendenti dallo schema e una gran quantità
di software impiegato già elabora gli URI di schemi ben conosciuti.
Introdurre un nuovo schema di URI richiede lo sviluppo e l'impiego non
solo del software client per
trattare lo schema, ma anche di agenti ausiliari come gateway, proxy e cache. Si veda [RFC2718] per altre considerazioni e costi relativi alla
progettazione degli schemi di URI.
A causa di questi costi, se esiste uno schema di
URI che incontra le necessità di un applicativo, i progettisti dovrebbero
usarlo piuttosto che inventarne uno.
Buona prassi: Riutilizzo degli
schemi di URI
Una specifica DOVREBBE
riutilizzare uno schema di URI esistente (piuttosto che crearne uno nuovo)
quando fornisce le proprietà di identificatori desiderate e la loro
relazione alle risorse.
Consideriamo il nostro
scenario di viaggio: l'agente che fornsice informazioni riguardo
al tempo di Oaxaca dovrebbe registrare un nuovo schema di URI per il "meteo"
per l'identificazione di risorse relative al tempo? Loro potrebbero quindi
pubblicare URI come "weather://travel.example.com/oaxaca". Quando un agente
software segue il riferimento di un tale URI, se ciò che accade in realtà è che un GET
HTTP viene invocato per reperire una rappresentazione della risorsa, allora
un URI "http" dovrebbe bastare.
L'Autorità per i Numeri Assegnati in
Internet {Internet Assigned Numbers Authority} (IANA)
mantiene un registro [IANASchemes] delle corrispondenze fra nomi di schemi di URI
e specifiche di schema.
Per esempio, il registro IANA indica che lo schema "http" è definito
nella [RFC2616]. Il processo di registrazione di un nuovo schema di URI
è definito nella [RFC2717].
Schemi di URI non registrati NON DOVREBBERO
essere impiegati per una serie di ragioni:
- Non esiste una maniera generalmente accettata per localizzare la
specifica di schema.
- Qualcun altro potrebbe usare lo schema per altri scopi.
- Non ci si dovrebbe aspettare che un software a scopo generico faccia
qualcosa di utile con gli URI di questo schema al di là della
comparazione di URI.
Una motivazione sconsiderata per
registrare un nuovo schema di URI è consentire a un agente software
di lanciare un particolare applicativo quando reperisce una
rappresentazione. La stessa cosa può essere compiuta con minor dispendio
spedendo al suo posto il tipo della rappresentazione, permettendo in tal modo
l'uso di protocolli e implementazioni di trasferimento esistenti.
Perfino se un agente non è in grado di
processare i dati della rappresentazione di un formato sconosciuto, esso
può almeno reperirlo. I dati potrebbero contenere informazione sufficiente
per permettere all'utente o all'agente utente di farne un qualche uso.
Quando un agente non gestisce un nuovo schema di URI, non può
reperire una rappresentazione.
Quando si progetta un nuovo formato di dati, il
meccanismo preferenziale per promuovere il suo impiego sul Web è il
tipo di media per Internet (si veda
Tipi di Rappresentazione eTipi di Media per Internet (§3.2)). I
tipi di media forniscono anche i mezzi per costruire nuovi applicazioni
informative, come descritto in
direzioni future per i formati di dati (§4.6).
Si sta tentando di indovinare la natura di una
risorsa con l'ispezione di un URI che lo identifica. Tuttavia, il Web è
progettato in modo che gli agenti comunichino lo stato dell'informazione
della risorsa attraverso
rappresentazioni, non identificatori. In generale, non si può
determinare il tipo di una rappresentazione di risorsa ispezionando un URI
della risorsa stessa. Ad esempio, l'"html" alla fine di "http://example.com/page.html"
non fornisce alcuna garanzia che le rappresentazioni della risorsa
identificata saranno servite con il tipo di media per Internet "text/html".
Colui che pubblica è libero di allocare identificatori e definire come essi
debbano essere serviti. Il protocollo HTTP non vincola il tipo di media per
Internet basato sul componente di percorso
dell'URI;
il proprietario dell'URI è libero di configurare il server a restituire
una rappresentazione usando PNG o qualsiasi altro formato di dati.
Lo stato della risorsa potrebbe evolvere nel
tempo. Richiedere a un proprietario di URI di pubblicare un nuovo URI per
ogni modifica nello stato della risorsa condurrebbe a un numero
significativo di riferimenti spezzati. Per robustezza, l'architettura Web
promuove l'indipendenza fra un identificatore e lo stato della risorsa
identificata.
Buona prassi:
Opacità dell'URI
Gli agenti che fanno uso degli
URI NON DOVREBBERO tentare di dedurre le proprietà della risorsa
referenziata.
In pratica, sono poche le deduzioni che possono
esser fatte poiché esse sono esplicitamente autorizzate dalle relative
specifiche. Alcune di queste deduzioni sono trattate nei dettagli per reperire una rappresentazione (§3.1.1).
L'URI d'esempio utilizzato nello
scenario di viaggio ("http://weather.example.com/oaxaca") suggerisce
a un lettore umano che la risorsa identificata ha qualcosa a che fare con il
tempo a Oaxaca. Un sito che riferisca del tempo a Oaxaca potrebbe essere
identificato proprio facilmente dall'URI "http://vjc.example.com/315". E l'URI "http://weather.example.com/vancouver"
potrebbe identificare la risorsa "il mio album di foto".
D'altro canto, l'URI "mailto:joe@example.com" indica
che l'URI si riferisce a una casella di posta. La specifica di schema di URI
per "mailto" autorizza gli agenti a dedurre che gli URI in questa forma
identificano caselle di posta su Internet.
Alcune autorità di assegnazione di URI
documentano e pubblicano i le loro politiche di assegnazione di URI. Per
informazioni aggiuntive riguardo l'opacità di URI, si vedano le questioni
del TAG metaDataInURI-31 e siteData-36.
Aneddoto
Quando sfoglia il documento XHTML che Nadia
riceve come rappresentazione della risorsa identificata da "http://weather.example.com/oaxaca",
ella trova che l'URI "http://weather.example.com/oaxaca#weekend" si
riferisce alla parte delle rappresentazione che comunica l'informazione
riguardo alla previsione per il fine settimana. Questo URI include
l'identificatore di frammento "weekend" (la stringa dopo il "#").
L'identificatore
di frammento componente di un URI permette l'identificazione
indiretta di una risorsa secondaria
attraverso il riferimento a una risorsa primaria e a informazioni
identificative aggiuntive.
La risorsa secondaria potrebbe essere una porzione o un sottoinsieme
della risorsa primaria, qualche panoramica sulle rappresentazioni della
risorsa primaria o qualche altra risorsa definita o descritta da quelle
rappresentazioni. I termini "risorsa primaria" e "risorsa secondaria" sono
definiti nella sezione 3.5 di [URI].
I termini "primaria" e "secondaria" in questo
contesto non limitano la natura della risorsa — non sono classi. In questo
contesto, primaria e secondaria indicano semplicemente che esiste una
relazione fra le risorse per gli scopi di un unico URI: l'URI con un
identificatore di frammento. Qualsiasi risorsa può identificarsi come una
risorsa secondaria. Potrebbe anche essere identificata impiegando un URI
senza un identifcatore di frammento e una risorsa potrebbe essere
identificata come una risorsa secondaria attraverso molteplici URI. Il fine
di questi termini è porre l'attenzione sulla relazione fra le risorse
stesse, non limitare la natura di una risorsa.
L'interpretazione degli identificatori di
frammento è trattata nella sezione sui
tipi di media e la semantica dell'identificatore di frammento (§3.2.1).
Si veda la questione del TAG
abstractComponentRefs-37, che riguarda l'impiego
dell'identificatore di frammento con i nomi del namespace per identificare
componenti astratti.
Rimangono aperte le questioni riguardanti gli
identificatori sul Web.
L'integrazione degli identificatori
internazionalizzati (cioè, composti di caratteri ulteriori rispetto a
quelli permessi da [URI]) all'interno dell'architettura Web è una questione
importante e aperta.
Si veda la questione del TAG
IRIEverywhere-27 per una trattazione sull'avanzamento dei lavori
in quest'area.
Tecnologie emergenti per un
Web Semantico, incluso il "Linguaggio dell'Ontologia per il Web {Web Ontology
Language} (OWL)" [OWL10], definisce le proprietà RDF come sameAs per
asserire che due URI identificano la stessa risorsa o inverseFunctionalProperty
per sottintenderla.
La comunicazione sulle risorse fra agenti in una
rete coinvolge URI, messaggi e dati. I protocolli del Web (compresi
HTTP, FTP, SOAP, NNTP e SMTP) sono basati sullo scambio di messaggi. Un messaggio potrebbe includere dati
come pure metadati riguardanti una risorsa (come le intestazioni HTTP "Alternates"
e "Vary"),
i dati del messaggio e il messaggio stesso (come l'intestazione HTTP "Transfer-encoding").
Un messaggio potrebbe perfino includere metadati riguardo i metadati del
messaggio (controlli per l'integrità del messaggio, per esempio).
Aneddoto
Nadia segue un collegamento ipertestuale
etichettato "immagine satellitare" aspettandosi di reperire una foto
satellitare della regione di Oaxaca. Il collegamento all'immagine dal
satellite è un collegamento XHTML codificato come <a
href="http://example.com/satimage/oaxaca">satellite image</a>.
Il browser di Nadia analizza l'URI e determina che il suo schema è "http". La configurazione del browser determina come
esso localizza l'informazione identificata, che potrebbe avvenire
attraverso una cache di precedenti azioni di reperimento, o contattando un
intermediario (come un server proxy), oppure con accesso diretto al server
identificato dalla porzione dell'URI. In questo esempio, il browser apre
una connessione di rete con la porta 80 sul server presso "example.com" e
invia un messaggio "GET" come specificato dal protocollo HTTP, richiedendo
una rappresentazione della risorsa.
Il server invia un messaggio di risposta al
browser, una volta ancora in accordo al protocollo HTTP. Il messaggio
consiste in alcune intestazioni e in un'immagine JPEG. Il browser legge le
intestazioni, apprende dal campo "Content-Type" che il tipo di media per
Internet della rappresentazione è "image/jpeg", legge la sequenza di
ottetti che costituiscono i dati della rappresentazione e presenta
l'immagine.
Questa sezione descrive i principi e i vincoli
architetturali che riguardano le interazioni fra agenti, compresi argomenti
come i protocolli di rete e gli stili di interazione, in parallelo con le
interazioni tra il Web come sistema e le persone che ne fanno uso. Il fatto
che il Web è un sistema altamente distribuito influenza i vincoli e gli
assunti architetturali sulle interazioni.
Gli agenti potrebbero usare un URI per accedere
alla risorsa referenziata; questo è chiamato seguire il riferimento dell'URI. L'accesso può assumere
molte forme, compresi il reperimento di una rappresentazione della risorsa
(per esempio, usando GET e HEAD di HTTP), l'aggiunta o la modifica di una
rappresentazione della risorsa (per esempio, usando POST o PUT di HTTP, che
in alcuni casi potrebbe cambiare lo stato attuale della risorsa se le
rappresentazioni sottoposte sono interpretate come istruzioni per quel fine)
e la cancellazione di alcune o di tutte le rappresentazioni della risorsa
(per esempio, usando DELETE di HTTP, che in alcuni casi potrebbe risultare
in una cancellazione della risorsa stessa).
Potrebbe esistere più di una maniera per
accedere a una risorsa per un dato URI; il contesto dell'applicazione
determina quale metodo di accesso usa un agente. Per esempio, un browser
potrebbe usare GET di HTTP per reperire una rappresentazione della risorsa,
laddove un controllore di collegamento ipertestuale potrebbe usare HEAD di
HTTP sullo stesso URI semplicemente per stabilire se è disponibile una
rappresentazione. Alcuni schemi di URI pongono le aspettative circa i metodi
di accesso disponibili, altri no (come lo schema URN [RFC 2141]). La sezione 1.2.2 di [URI] tratta della separazione dell'identificazione e
dell'interazioni in maggior dettaglio. Per informazioni aggiuntive circa le
relazioni fra metodi di accesso multipli e indirizzabilità dell'URI, si veda
la conclusione del TAG "URI,
Indirizzabilità e l'uso di GET e POST in HTTP".
Sebbene molti
schemi di URI (§2.4) vengano associati allo stesso nome dei
protocolli, ciò non implica che l'uso di tali URI sfocerà necessariamente in
un accesso alla risorsa attraverso il protocollo che ha quel nome. Perfino
quando un agente impiega un URI per reperire una rappresentazione,
quell'accesso potrebbe avvenire attraverso gateway, proxy, cache e servizi
di risoluzione dei nomi i quali sono indipendenti dal protocollo associato
con il nome dello schema.
Molti schemi di URI definiscono un protocollo di
interazione predefinito per tentare di accedere a una risorsa identificata.
Quel protocollo di interazione è spesso la base per allocare gli
identificatori entro quello schema, proprio come gli URI "http" sono
definiti in termini di server HTTP basati su TCP. Comunque, ciò non implica
che tutta l'interazione con tali risorse è limitata al protocollo di
interazione predefinito. Ad esempio, i sistemi di reperimento dell'informaizone
spesso fanno uso di proxy per interagire con una moltitudine di schemi di
URI, come i proxy HTTP che vengono impiegati per accedere a risorse "ftp" e
"wais". I proxy possono anche fornire servizi avanzati, come i proxy di
annotazione, i quali combinano il normale reperimento dell'informazione con
il reperimento aggiuntivo di metadati per fornire un visione unitaria e
multidimensionale delle risorse che usano lo stesso protocollo e agenti
utente come il Web non annotato. In maniera similare, potrebbero essere
definiti protocolli futuri che ricomprendono i nostri sistemi attuali,
usando meccanismi di interazione completamente differenti, senza cambiare
gli schemi degli identificatori esistenti. Si veda anche,
principio delle specifiche ortogonali (§5.1).
Seguire il riferimento di un URI generalmente coinvolge
una successione di passi come descritto nelle molteplici specifiche e
implementato dall'agente. L'esempio seguente illustra la serie di
specifiche che governano il processo di quando un agente utente è istruito
per seguire un collegamento ipertestuale (§4.4) che fa parte di un documento SVG.
In questo esempio, l'URI è "http://weather.example.com/oaxaca" e il
contesto dell'applicazione richiede all'agente utente di reperire e
presentare una rappresentazione della risorsa identificata.
- Dal momento che l'URI fa parte di un collegamento ipertestuale in un
documento SVG, la prima specifica relativa è la Raccomandazione SVG
1.1 [SVG11]. La
sezione 17.1 di queste specifiche importa la semantica del
collegamento definita in XLink 1.0 [XLink10]: "La risorsa remota (la destinazione del collegamento)
è definita da un URI specificato dall'attributo di XLink
href
nell'elemento 'a'". La specifica SVG va avanti affermando
che l'interpretazione di un elemento a implica reperire una
rappresentazione di una risorsa, identificata dall'attributo href
nel namespace di XLink: "Attivando questi collegamenti (facendo click
con il mouse, attraverso l'input da tastiera, con comandi vocali, etc.),
gli utenti possono visitare queste risorse".
- La specifica XLink 1.0 [XLink10], che definisce l'attributo
href nella
sezione 5.4, stabilisce che "Il valore dell'attributo href deve essere
un riferimento URI come definito nella [IETF RFC 2396], oppure deve
risolversi in un riferimento URI dopo che gli sia stata applicata la
conversione in caratteri escape descritta appresso".
- La specifica URI [URI] stabilisce che "Ogni URI comincia con un nome di schema
che si riferisce a una specifica per assegnare gli identificatori entro
quello schema". Il nome dello schema di URI in questo esempio è "http".
- [IANASchemes] stabilisce che lo schema "http" è definito dalla
specifica di
HTTP/1.1 (RFC 2616 [RFC2616], sezione 3.2.2).
- In questo contesto SVG, l'agente costruisce una richiesta GET di
HTTP (sezione 9.3 di [RFC2616]) per reperire la rappresentazione.
- La sezione 6 di [RFC2616] definisce come il server costruisce un messaggio di
risposta corrispondente, compreso il campo 'Content-Type'.
- La sezione 1.4 di [RFC2616] stabilisce che "la comunicazione HTTP di solito prende
luogo su connessioni TCP/IP". Questo esempio non indirizza né a quel
passaggio nel processo, né ad altri passaggi come la risoluzione del
Sistema di Nome di Dominio {Domain Name System} (DNS).
- L'agente interpreta la rappresentazione restituita in accordo alla
specifica del formato dei dati che corrisponde alla rappresentazione dei
Tipi di Media per Internet (§3.2) (il valore del 'Content-Type'
di HTTP) nel relativo registro IANA [MEDIATYPEREG].
Quali rappresentazioni siano precisamente
reperite dipende da un certo numero di fattori, compresi:
- Se il proprietario dell'URI rende disponibile una rappresentazione
qualsiasi;
- Se l'agente che fa la richiesta ha i privilegi di accesso per quelle
rappresentazioni (si veda la sezione su
collegamento e controllo di accesso (§3.5.2));
- Se il proprietario dell'URI ha fornito più di una rappresentazione
(in differenti formati come HTML, PNG o RDF; in differenti lingue come
l'inglese e lo spagnolo; oppure trasformato dinamicamente in accordo
alle capacità hardware e software del contenitore), la rappresentazione
risultante potrebbe dipendere dalla negoziazione fra l'agente utente e
il server.
- Il momento della richiesta; il mondo cambia nel tempo, così anche le
rappresentazioni delle risorse è normale che cambino nel tempo.
Assumendo che una rappresentazione sia stata
reperita con successo, il potere espressivo del formato della
rappresentazione influirà su come il fornitore della rappresentazione
comunica precisamente lo stato della risorsa. Se la rappresentazione
comunica lo stato della risorsa in maniera non accurata, questa
inaccuratezza o ambiguità potrebbe condurre a confusione fra gli utenti
rispetto a cosa sia la risorsa. Se utenti diversi raggiungono conclusioni
differenti su cosa sia la risorsa, essi potrebbero interpretare ciò come
una collisione di URI (§2.2.1). Alcune comunità, come quelle che
sviluppano il Web Semantico, cercano di fornire una cornice per comunicare
in modo accurato la semantica di una risorsa in una maniera leggibile per
una macchina. La semantica leggibile da una macchina potrebbero alleviare
alcune delle ambiguità associate con linguaggio naturale di descrizioni
delle risorse.
Una rappresentazione sono dati che codificano
informazione riguardo lo stato di una risorsa. Le rappresentazioni non
necessariamente descrivere la risorsa o ritraggono una parvenza
della risorsa o rappresentano la risorsa in altri significati della parola
"rappresentare".
Le rappresentazioni di una risorsa potrebbe
essere inviata o ricevuta usando i protocolli di interazione. Questi
protocolli a turno determinano la forma in cui le rappresentazioni vengono
convogliate sul Web. HTTP, ad esempio, fornisce per la trasmissione delle
rappresentazioni come flussi di ottetti tipizzati impiegando i tipi di media
per Internet [RFC2046].
Proprio com'è importante riutilizzare schemi di
URI esistenti ogni volta che sia possibile, esistono benefici significativi
nell'usare flussi di media
tipizzati in ottetti per le rappresentazioni perfino nel caso poco usuale
in cui un nuovo schema di URI e il protocollo ad esso associato sia da
definire. Ad esempio, se il tempo di Oaxaca fosse stato dirottato sul
browser di Nadia impiegando un protocollo diverso da HTTP, allora il
software per presentare i formati come text/xhmtl+xml e image/png sarebbe
stato ancora utilizzabile se il nuovo protocollo supportasse la trasmissione
di quei tipi. Questo è un esempio del
principio delle specifiche ortogonali (§5.1).
Buona prassi: Riutilizzo dei formati di
rappresentazione
I nuovi protocolli creati per
il Web DOVREBBERO trasmettere le rappresentazioni come flussi di ottetti
tipizzati per i tipi di media per Internet.
Il meccanismo del tipo di media per Internet in
effetti ha qualche limitazione. Per esempio, i tipi di media stringhe non
supportano il tracciamento della versione (§4.2.1) o altri parametri. Si
vedano le questioni del TAG
uriMediaType-9 e mediaTypeManagement-45 che si occupano degli aspetti del
meccanismo del tipo di media.
Il Tipo di Media per Internet definisce la
sintassi e la semantica dell'identificatore di frammento (introdotto in
Identificatori di Frammento (§2.6)), se presente, che potrebbe
essere utilizzato in congiunzione con una rappresentazione.
Aneddoto
In una delle sue pagine XHTML, Dirk crea
un collegamento ipertestuale a un'immagine che Nadia ha pubblicato sul
Web. Egli crea un collegamento ipertestuale con <a href="http://www.example.com/images/nadia#hat">Nadia's
hat</a>. Emma vede la pagina XHTML di Dirk nel suo
browser Web e segue il collegamento. L'implementazione HTML nel suo
browser rimuove il frammento dall'URI e richiede l'immagine "http://www.example.com/images/nadia".
Nadia serve una rappresentazione SVG dell'immagine (con il tipo di
media per Internet "image/svg+xml"). Il browser Web di Emma fa partire
un'implementazione SVG per far vedere l'immagine. Esso passa l'URI
originale compreso il frammento, "http://www.example.com/images/nadia#hat"
a questa implementazione, causando la visione del cappello da essere
mostrata piuttosto che l'immagine completa.
Si noti che l'implementazione HTML nel browser
di Emma non necessita di comprendere la sintassi o la semantica
del frammento SVG (né l'implementazione SVG deve nemmeno comprendere
HTML, WebCGM, RDF ... sintassi di frammento o semantica; deve
semplicemente riconoscere il delimitatore # dalla sintassi URI [URI] e
rimuovere il frammento quando accede alla risorsa). Questa ortogonalità (§5.1) è una caratteristica importante
dell'architettura Web;
è ciò che mette in condizione il browser di Emma di fornire un servizio
utile senza richiedere un aggiornamento.
La semantica di un identificatore di frammento
sono definite dall'insieme di rappresentazioni che potrebbero risultare da
un'azione di reperimento della risorsa primaria. Il formato e la
risoluzione del frammento sono perciò dipendenti dal tipo di
rappresentazione potenzialmente reperibile, nonostante tale reperimento
sia compiuto solo se viene seguito il riferimento dell'URI. Se una tale rappresentazione
non esiste, allora la semantica del frammento sono considerate sconosciute
e, in effetti, svincolata. La semantica dell'identificatore di frammento
sono ortogonali agli schemi di URI e in tal modo non può essere ridefinito
dalle specifiche dello schema di dell'URI.
L'interpretazione dell'identificatore di
frammento è portata a termine solamente dall'agente che segue il
riferimento di un
URI; l'identificatore di frammento non è passato ad altri sistemi durante
il processo di reperimento. Ciò significa che alcuni intermediari
nell'architettura Web (come i proxy) non hanno alcuna interazione con gli
identificatori di frammento e che il reindirizzamento (in HTTP [RFC2616], ad esempio) non si occupa dei frammenti.
La negoziazione
del contenuto si riferisce alla prassi di rendere disponibili
molteplici rappresentazioni attraverso lo stesso URI. La negoziazione fra
l'agente richiedente e il server determina quale rappresentazione viene
servita (di solito con l'obiettivo di servire la "migliore"
rappresentazione che un agente ricevente possa processare). HTTP è un
esempio di un protocollo che mette i fornitori di rappresentazione in
condizioni di impiegare la negoziazione di contenuto.
I singoli formati di dati potrebbero definire
le loro proprie regole per l'utilizzo della sintassi dell'identificatore
di frammento per specificare tipi differenti di sottoinsiemi, viste o
riferimenti esterne che sono identificabili come risorse secondarie da
quel tipo di media. Perciò, i fornitori di rappresentazione devono gestire
con attenzione la negoziazione del contenuto quando utilizzata con un URI
che contiene un identificatore di frammento. Si consideri un esempio in
cui il proprietario dell'URI "http://weather.example.com/oaxaca/map#zicatela" utilizza
la negoziazione del contenuto per servire due rappresentazioni della
risorsa identificata. Possono insorgere tre situazioni:
- L'interpretazione di "zicatela" è definita in maniera consistente da
entrambe le specifiche del formato di dati. Il fornitore di
rappresentazione decide quando le definizioni della semantica
dell'identificatore di frammento sono sufficientemente consistenti.
- L'interpretazione di "zicatela" è definita in maniera inconsistente
dalle specifiche del formato di dati.
- L'interpretazione di "zicatela" è definita in una sola specifica di
formato di dati, ma non nell'altra.
La prima situazione — semantica consistente —
non pone problemi.
Il secondo caso è un errore della gestione del
server: i fornitori di rappresentazione non devono utilizzare la
negoziazione di contenuto per servire formati di rappresentazione che
hanno una semantica dell'identificatore di frammento inconsistente. Questa
situazione conduce anche alla
collisione di URI (§2.2.1).
Il terzo caso non è un errore della gestione
del server. È un mezzo con il quale il Web può crescere. Poiché il
Web è un sistema distribuito nel quale formati e agenti sono impiegati in
una maniera disomogenea, l'architettura Web non vincola gli autori a usare
solo i formati considerati il "minimo comun denominatore". Gli autori di
contenuto potrebbero avvantaggiarsi dei nuovi formati di dati mentre
continuano ad assicurare una ragionevole compatibilità all'indietro per
gli agenti che ancora non li implementano.
Nel terzo caso, il comportamento tenuto
dall'agente ricevente dovrebbe variare in funzione del fatto che il
formato negoziato definisca la semantica dell'identificatore di
frammento. Quando un formato di dati ricevuto non definisce la semantica
dell'identificatore di frammento, l'agente dovrebbe compiere un
recupero silente dell'errore a meno che l'utente abbia dato il
consenso; si veda [CUAP] per un comportamento suggerito dell'agente aggiuntivo in
questo caso.
Si veda la relativa questione del TAG RDFinXHTML-35.
La comunicazione avvenuta con successo fra due
parti dipende dalla comprensione ragionevolmente condivisa della semantica
dei messaggi scambiati, sia dei dati che dei metadati. A volte,
potrebbero esistere inconsistenze fra i dati e i metadati del messaggio del
mittente. Esempi, osservati nella pratica, di inconsistenze fra i dati e i
metadati della rappresentazione comprendono:
- L'attuale codifica di carattere di una rappresentazione (cioè, "iso-8859-1", specificata
dall'attributo
encoding in una dichiarazione XML)
è inconsistente con il parametro dell'insieme di caratteri nei metadati
della rappresentazione
(cioè, "utf-8", specificata dal campo 'Content-Type' in un'intestazione
HTTP).
- Il namespace (§4.5.3) dell'elemento radice dei dati della
rappresentazione XML (cioè, come specificata dall'attributo "xmlns") è
inconsistente con il valore del campo 'Content-Type' in un'intestazione
HTTP.
D'altro canto, non esiste alcuna inconsistenza
nel servire un contenuto HTML con il tipo di media "text/plain", ad esempio,
poiché questa combinazione è autorizzata dalle specifiche.
Gli agenti riceventi dovrebbero scovare le
inconsistenze di protocollo e compiere un adeguato
recupero dell'errore.
Vincolo:
Inconsistenza dati-metadati
Gli agenti NON DEVONO
ignorare i metadati del messaggio senza il consenso dell'utente.
In tal modo, ad esempio, se le parti
responsabili per "weather.example.com" etichettano per errore la foto
satellitare di Oaxaca come "image/gif" invece di "image/jpeg", e se il
browser di Nadia rileva un prolema, il browser di Nadia non deve ignorare il
problema (cioè, presentare semplicemente l'immagine JPEG) senza il consenso
di Nadia. Il browser di Nadia può renderle noto il problema oppure
notificarlo e compiere un'azione correttiva.
Inoltre, i fornitori di rappresentazione possono
aiutare a ridurre il rischio di inconsistenze attraverso l'assegnazione
attenta dei metadati della rappresentazione (in special modo quelli che si
applicano a rappresentazioni che s'incrociano). La sezione sui tipi di media per XML (§4.5.7) presenta un esempio di riduzione
del rischio di errore fornendo nessun metadato riguardo alla codifica di
carattere quando si serve dell'XML.
L'accuratezza dei metadati poggia sugli
amministratori di server, gli autori delle rappresentazioni e il software
che utilizzano. in pratica, le capacità degli strumenti e le relazioni
sociali potrebbero essere i fattori limitanti.
L'accuratezza di questi e altri campi di
metadati è importante per le dinamiche risorse Web, dove un pochino di
ragionamento e programmazione può spesso assicurare metadati corretti per un
vasto numero di risorse.
Spesso esiste una separazione del controllo fra
gli utenti che creano le risorse delle rappresentazioni e i gestori dei
server che manutengono il software del sito Web. Dato che in genere è il
software del sito Web che fornisce i metadati associati ad una risorsa, ne
consegue che è richiesta la coordinazione fra i gestori dei server e i
creatori di contenuto.
Buona prassi:
Associazione
di metadati
I gestori di server DOVREBBERO
permettere ai creatori della rappresentazione di controllare i metadati
associati alle loro rappresentazioni.
In particolare, i creatori di contenuto
necessitano di essere in grado di controllare il tipo di contenuto (per
estensibilità) e la codifica di carattere (per un'adeguata
internazionalizzazione).
La conclusione del TAG "Metadati
autoritativi" spiega in maggior dettaglio come trattare
l'inconsistenza dati/metadati e come può essere usata la configurazione del
server per evitarla.
Il reperimento di Nadia dell'informazione meteo
(un esempio di un'interrogazione di sola lettura o di ricerca) si qualifica
come una interazione "sicura"; una
interazione sicura
è quella in cui l'agente non impone alcun obbligo al di là dell'interazione.
Un agente potrebbe imporre un obbligo attraverso altri mezzi (come con la
firma di un contratto). Se un agente non contrae un obbligo prima di
un'interazione sicura, non deve contrarla in seguito.
Altre interazioni Web assomigliano ad ordini più
che a interrogazioni. Queste
interazioni insicure potrebbero
causare una modifica nello stato di una risorsa e l'utente potrebbe essere
ritenuto responsabile per le conseguenze di queste interazioni. Le
interazioni non sicure includono sottoscrivere una newsletter, scrivere ad
una lista o modificare un database. Nota: In
questo contesto, la parola "insicura" non significa necessariamente
"pericolosa"; il termine "sicuro" è usato nella sezione 9.1.1 della [RFC2616] e "insicuro" è il naturale contrario.
Aneddoto
Nadia decide di prenotare una vacanza a
Oaxaca presso "booking.example.com". Ella inserisce i dati in una serie
di moduli online e alla fine le viene domandata l'informazione della
carta di credito per acquistare i biglietti aerei. Ella fornisce questa
informazione in un altro modulo. Quando preme il pulsante "Acquista", il
suo browser apre un'altra connessione di rete al server presso "booking.example.com"
e invia un messaggio composto dai dati del modulo usando il metodo POST.
Questa è una interazione non sicura; Nadia desidera cambiare lo stato del
sistema scambiando denaro per dei biglietti aerei.
Il server legge la richiesta POST e dopo
aver ultimato la transazione della prenotazione restituisce un messaggio
al browser di Nadia che contiene una rappresentazione dei risultati
della richiesta di Nadia. I dati della rappresentazione sono in XHTML
cosicché possono essere salvati o stampati per l'archivio di Nadia.
Si noti che né i dati trasmessi con POST, né
i dati ricevuti in risposta corrispondono necessariamente ad una
qualsiasi risorsa identificata da un URI.
Le interazioni sicure sono importanti perché
queste sono interazioni dove gli utenti possono navigare tranquilli e dove
gli agenti (compresi i motori di ricerca e i browser che pre-immagazzinano i
dati per l'utente) possono seguire i collegamenti ipertestuali in modo
sicuro. Gli utenti (o gli agenti che agiscono in loro vece) non si impegnano
a far nulla se non a interrogare una risorsa o a seguire un collegamento
ipertestuale.
Principio:
Reperimento sicuro
Gli agenti non contraggono
obblighi reperendo una rappresentazione.
Per esempio, è scorretto pubblicare un URI che,
quando viene seguito come parte di un collegamento ipertestuale, iscrive un
utente ad una mailing list. Si ricordi che i motori di ricerca potrebbero
seguire tali collegamenti ipertestuali.
Il fatto che il GET HTTP, il metodo d'accesso
più di frequente utilizzato quando si segue un collegamento ipertestuale, è
sicuro non implica che tutte le interazioni sicure debbano essere fatte
attraverso il GET di HTTP. A volte, potrebbero esistere buone ragioni (come
requisiti di riservatezza o limiti pratici sulla lunghezza dell'URI) a
condurre un'operzione altrimenti sicura a usare un meccanismo in genere
riservata a operazioni insicure (cioè, il POST di HTTP).
Per maggiori informazioni riguardo le operazioni
sicure e insicure nell'usare GET e POST di HTTP e nel trattare aspetti di
sicurezza intorno all'uso di GET di HTTP, si veda la conclusione del TAG "URI,
Indirizzabilità e l'uso di GET e POST in HTTP".
Aneddoto
Nadia paga i suoi biglietti aerei
(attraverso un'interazione POST come sopra descritta). Ella riceve una
pagina Web con l'informazione della conferma e desidera rubricarla
cosicché può riferirsi ad essa quando calcola le sue spese. Sebbene
Nadia puo stampare i risultati oppure salvarli in un file, le
piacerebbe anche rubricarle.
Le richieste di transazione e i risultati sono
risorse valutabili e, come tutte le risorse valutabili, è utile riferirsi
ad esse con un pURI persistente (§3.5.1). Comunque, in pratica, Nadia non può
rubricare il suo impegno a pagare (espresso attraverso la richiesta POST)
o la quietanza e l'impegno della compagnia aerea a fornirle un volo
(espresso attraverso la risposta al POST).
Esistono modi per fornire URI persistenti per
richieste di transazione e i loro risultati. Per le richieste di
transazione,gli agenti utenti possono fornire un'interfaccia per gestire
le transazioni dove l'utente agente abbia contratto un obbligazione in
vece dell'utente. Per i risultatti delle transazioni, HTTP consente ai
fornitori di rappresentazione di associare un URI con i risultati di una
richiesta POST di HTTP usando l'intestazione "Content-Location"
(descritta nella sezione 14.14 della [RFC2616]).
Aneddoto
Dal momento che Nadia trova utile il sito
meteo di Oaxaca, spedisce per posta elettronica una recensione al suo
amico raccomandando che controlli 'http://weather.example.com/oaxaca'. Dirk
fa click sul collegamento ipertestuale risultante nel messaggio di posta
elettronica che ha ricevuto e rimane frustrato per un 404 (non trovato).
Dirk tenta ancora il giorno successivo e riceve una rappresentazione con
"notizie" che è vecchia di due settimane. Egli tenta ancora una volta il
giorno dopo per ricevere solo una rappresentazione che afferma che il
tempo a Oaxaca è soleggiato, nonostante i suoi amici a Oaxaca gli dicano
al telefono che in realtà sta piovendo. Dirk e Nadia concludono che i
proprietari dell'URI sono inaffidabili o imprevedibili. Sebbene il
proprietario dell'URI abbia scelto il Web come medium di comunicazione,
il proprietario ha perso due clienti a causa di una gestione non
realistica della rappresentazione.
Un proprietario di URI potrebbe mettere a
disposizione zero o più rappresentazioni autoritative della risorsa
identificata da quell'URI. Esiste un beneficio per la comunità nel fornire
le rappresentazioni.
Buona prassi:
Rappresentazione disponibile
Un proprietario URI DOVREBBE
fornire rappresentazioni della risorsa che identifica.
Ad esempio, i proprietari degli URI del
namespace XML dovrebbero usarli per identificare un
documento del namespace (§4.5.4).
Solo perché le rappresentazioni sono disponibili
non significa che è sempre desiderabile recuperarle. Infatti, in alcuni casi
è vero il contrario.
Principio:
Fare un riferimento non
implica seguire quel riferimento
Uno sviluppatore di applicazioni
o un autore di specifica NON DOVREBBE richiedere il reperimento in rete
delle rappresentazioni ogni volta che ci si riferisce ad esse.
Seguire un riferimento URI ha un costo
(potenzialmente significativo) nelle risorse di calcolo e della larghezza di banda,
potrebbe avere implicazioni di sicurezza e potrebbe imporre una latenza
significativa all'applicazione che segue il riferimento. Tranne quando
necessario, si dovrebbe evitare di seguire il riferimento dell'URI.
Le sezioni seguenti discutono alcuni aspetti
della gestione della rappresentazione, compresi promuovere la
persistenza dell'URI (§3.5.1), gestire l'accesso alle risorse (§3.5.2) e
supportare la navigazione (§3.5.3).
Come nel caso di molte interazioni umane, la
riservatezza nelle interazioni via Web dipende dalla stabilità e la
predicibilità. Per una risorsa informativa, la persistenza dipende dalla
consistenza delle rappresentazioni. Il fornitore della rappresentazione
stabilisce quando le rappresentazioni sono sufficientemente consistenti
(sebbene quella determinazione in genere prende in considerazione le aspettative dell'utente).
Sebbene la persistenza in questo caso è
osservabile come un risultato del reperimento della rappresentazione, il
termine persistenza dell'URI è utilizzato per
descrivere la proprietà desiderabile che, una volta associata con un
arisorsa, un URI dovrebbe continuare indefinitivamente a rifersi a quella
risorsa.
Buona prassi:
Rappresentazione consistente
Un proprietario di URI
DOVREBBE fornire rappresentazioni della risorsa identificata in maniera
consistente e predicibile.
La persistenza di URI è una questione di
condotta e da parte del proprietario dell'URI. Lascelta di un particolare schema di URI
fnon fornisce alcuna garanzia che quegli URI saranno persistenti o che non
saranno persistenti.
HTTP [RFC2616] è stato progettato per aiutare a gestire la persistenza
degli URI. Ad esempio, il reindirizzamento HTTP (usando i codici di
risposta 3xx) permette ai server di dire ad un agente che occorre che esso
compia un'ulteriore azione al fine di completare la richiesta (ad esempio,
è associato un nuovo URI alla risorsa).
In aggiunta, anche la
negoziazione del contenuto promuove la consistenza, dacché non si
richiede ad un gestore di sito di definire nuovi URI quando aggiunge il
supporto per una nuova specifica di formato. I protocolli che non
supportano la negoziazione del contenuto (come FTP) richiedono un nuovo
identificatore quando viene introdotto un nuovo formato di dati. L'uso
improprio della negoziazione del contenuto può portare a rappresentazioni
inconsistenti.
Per spiegazioni aggiuntive riguardo la
persistenza dell'URI,
si veda [Cool].
È ragionevole limitare l'accesso ad una
risorsa (per ragioni commerciali o di sicurezza, ad esempio), ma
identificare semplicemente la risorsa è come riferirsi a un libro con il
titolo. In circostanze eccezionali, le persone potrebbero essere d'accordo
sul tenere riservati titoli o URI (ad esempio, l'autore di un libro e un
editore potrebbero essere d'accordo sul tenere l'URI della pagina
contenente materiale aggiuntivo segreto finché il libro sarà pubblicato),
altrimenti essi sono liberi di scambiarli.
Per analogia: i proprietari di un edificio
potrebbero avere come linea di condotta che il pubblico può entrare
nell'edificio solo attraverso il portone di fronte e solo durante l'orario
d'ufficio. Le persone che lavorano nell'edificio e che fanno consegne per
esso potrebbero usare altre porte come appropriate. Una tale politica
sarebbe rafforzata da una combinazione di personale di sicurezza e
dispositivi meccanici come lucchetti e pass. Non si dovrebbe rafforzare
questa politica nascondendo delle entrate dell'edificio, né richiedendo
una legislazione che imponga l'uso del portone di fronte e vieti a
chiunque di rivelare il fatto che esistono altre porte nell'edificio.
Aneddoto
Nadia invia a Dirk l'URI dell'articolo che
sta leggendo ora. Con il suo browser, Dirk segue il collegamento
ipertestuale e gli viene chiesto di inserire il nome utente e la
password di iscritto. Dal momento che Dirk è anche un iscritto ai
servizi forniti da "weather.example.com," egli può accedere alla
stessa informazione come Nadia. In tal modo, l'autorità per "weather.example.com"
può limitare l'accesso a gruppi autorizzati e fornire ancora i
benefici degli URI.
Il Web fornisce alcuni meccanismi per
controllare l'accesso alle risorse; questi meccanismi non si basano sul
nascondere o sopprimere gli URI per quelle risorse. Per informazioni
aggiuntive, si veda la conclusione del "'Collegare in
profondità' nel World Wide Web".
È un punto di forza dell'Architettura
Web che i collegamenti possono esser fatti e condivisi; un utente che ha
trovato una parte interessante del Web può condividere questa esperienza
semplicemente ripubblicando un URI.
Aneddoto
Nadia e Dirk vuole visitare il Museo delle
Previsioni Meteorologiche a Oaxaca. Nadia va su "http://maps.example.com",
localizza il museo e manda per posta l'URI "http://maps.example.com/oaxaca?lat=17.065;lon=-96.716;scale=6"
a
Dirk. Dirk va su "http://mymaps.example.com", localizza il museo e
manda per posta l'URI "http://mymaps.example.com/geo?sessionID=765345;userID=Dirk"
a
Nadia. Dirk legge il messaggio di posta elettronica di Nadia ed è in
grado di seguire il collegamento alla mappa. Nadia legge il messaggio
di Dirk, segue il collegamento e riceve un messaggio di errore 'Nessun
utente/sessione corrispondente'. Nadia deve ricominciare di nuovo da "http://mymaps.example.com"
e trovare il posto del museo ancora una volta.
Per le risorse che sono generate su richiesta,
la generazione meccanica di URI è comune. Per le risorse che potrebbe
essere utile rubricare per una successiva lettura attenta oppure condivise con altri,
i gestori di server dovrebbero
evitare di limitare senza necessità il riutilizzo di tali URI. Se l'intenzione è quella di restringere
l'informazione per un particolare utente, come potrebbe essere il caso di
un'applicazione di conto bancario online ad esempio, i progettisti
dovrebbero usare degli appropriati meccanismi di
controllo d'accesso (§3.5.2).
Anche le interazioni condotte con il POST di
HTTP (in cui potrebbe essere stato usato il GET di HTTP) limitano le
possibilità di navigazione. L'utente non può creare un segnalibro o
condividere un URI perché le transazioni POST di HTTP tipicamente non
producono come risultato un URI differente da quello con cui l'utente interagisce con il sito.
Rimangono questioni aperte riguardanti le
interazioni sul Web.
Il TAG si aspetta versioni future di questo documento per indirizzare in
maggior dettaglio la relazione fra l'architetuuta ivi descritta,
Web Services {Servizi Web},
sistemi peer-to-peer,
sistemi di messaggistica istantanea (come [RFC3920]), flussi audio (come RTSP [RFC2326]), e il voice-over-IP {voce-su-IP} (come SIP [RFC3261]).
Una specifica di formato di dati (ad esempio, per XHTML,
RDF/XML, SMIL, XLink, CSS e PNG) incorpora un accordo sulla corretta
interpretazione dei dati della rappresentazione. Il primo formato di dati utilizzato sul Web è
stato
HTML. Da quel momento in poi, i formati di dati sono cresciuti di numero.
L'architettura Web non pone vincoli su quali formati di dati i fornitori di
contenuto possano usare. Questa flessibilità è importante perché esiste
un'evoluzione costante nelle applicazioni, che si risolve in nuovi formati di
dati e raffinamenti di formati esistenti. Sebbene l'architettura Web
permetta l'impiego di nuovi formati di dati, la creazione e l'impiego di nuovi
formati (e gli agenti in grado di trattarli) sono dispendiosi. In tal modo, prima di
inventare un nuovo formato di dati (o un "meta" formato come XML), i
progettisti dovrebbero considerare con attenzione il riutilizzo di uno che sia
già disponibile.
Perché un formato di dati sia interoperabile in
modo utile fra due parti, le parti devono concordare (per una ragionevole
estensione) sulla sua sintassi e la sua semantica. La comprensione
condivisa di un formato di dati promuove l'interoperabilità, ma non implica
vincoli sull'utilizzo; per esempio, chi invia i dati non può contare sul fatto
di essere in grado di vincolare il comportamento di chi riceve i dati.
Di seguito descriviamo alcune caratteristiche di
un formato di dati che facilitano l'integrazione all'interno dell'architettura
Web. Questo documento in generale non
si indirizza alle caratteristiche vantaggiose
di una specifica come la leggibilità, la semplicità, l'attenzione agli
obiettivi del programmatore, l'attenzione alla necessità dell'utente,
l'accessibilità, né l'internazionalizzazione. La sezione sulle
specifiche architetturali (§7.1) include riferimenti alle linee
guida aggiuntive per la specifica di formato.
I formati di dati binari sono quelli in cui
porzioni dei dati sono codificati per l'uso diretto da parte dei processori
di computer, ad esempio little-endian 32 bit e IEEE 64 bit a virgola mobile
a precisione doppia. Le porzioni di dati così rappresentate comprendono
valori numerici, puntatori e dati compressi di ogni sorta.
Un formato di dati testuali è uno in cui i dati
sono specificati in una codifica definita come una sequenza di caratteri.
HTML, la posta elettronica Internet e tutti i
formati basati su XML (§4.5) sono testuali. Sempre di più, i
formati di dati testuali internazionalizzati si riferiscono al repertorio
Unicode [UNICODE] per le definizioni dei caratteri.
Se un formato di dati è testuale, come definito
in questa sezione, ciò non implica che dovrebbe essere servito con un tipo
di media iniziante con "text/". Sebbene i formati basati su XML sono
testuali, molti formati basati su XML non consistono principalmente di
elocuzioni nel linguaggio naturale. Si veda la sezione sui
tipi di media per XML (§4.5.7) per le questioni che sorgono
quando viene usato "text/" in congiunzione con un formato basato su XML.
In principio, tutti i dati sono rappresentati
utilizzando formati testuali. In pratica, alcuni tipi di contenuto (ovvero,
quelli audio e video) sono rappresentati in genere usando formati binari.
Le negoziazioni tra i formati di dati
binari e testuali sono complesse e dipendente dall'applicazione. I formati
binari possono essere significativamente più compatti, in particolare per
complesse strutture di dati ricche di puntatori. Inoltre, essi possono
essere consumati più rapidamente dagli agenti in quei casi in cui vengono
caricati in memoria e utilizzati senza nessuna o con minima conversione. Si
noti, comunque, che tali casi sono relativamente inusuali in quanto l'uso
diretto potrebbe aprire la porta a questioni di sicurezza alle quali ci si
può
indirizzare solo in maniera pratica esaminando in dettaglio ogni aspetto
della struttura di dati.
I formati testuali sono di solito più portabili
e interoperabili. I formati testuali inoltre hanno il considerevole
vantaggio che possono essere letti direttamente dagli esseri umani (e
compresi, data una sufficiente documentazione). Questo può semplificare i
compiti nel creare e manutenere il software e permettere l'intervento
diretto di umani nella catena dell'elaborazione senza il ricorso a strumenti
più complessi di un onnipresente editor testuale. Infine, esso semplifica il
compito necessariamente umano di imparare i nuovi formati di dati; questo è
ciò che viene chiamato l'effetto "vista codice".
È importante enfatizzare che l'intuizione
in merito a problemi che riguardano la dimensione dei dati e la velocità di
elaborazione non è una guida affidabile nella progettazione del formato;
studi quantitativi sono essenziali per una corretta comprensione delle
negoziazioni. Perciò, i progettisti della specifica di un formato
di dati dovrebbero fare una scelta ponderata fra il progetto di un formato
binario e testuale.
Si veda la questione del TAG
binaryXML-30.
In un mondo perfetto, i progettisti di
linguaggio inventerebbero linguaggi che incontrano alla perfezione i
requisiti che sono stati presentati loro, i requisiti sarebbero un modello
perfetto del mondo, non cambierebbero mai nel tempo e tutte le
implementazioni sarebbero perfettamente interoperabili perché le specifiche
non avrebbero alcuna variabilità.
Nel mondo reale, i progettisti di linguaggio non
s'indirizzano alla perfezione ai requisiti dacché li interpretano, i requisiti
danno un modello non accurato del mondo, vengono presentati requisiti in
conflitto fra loro e che cambiano nel tempo. Come risultato, i progettisti
negoziano con gli utenti, fanno compromessi e spesso introducono meccanismi
di estensibilità in modo tale che sia possibile lavorare intorno ai problemi
a breve termine. Sul lungo termine, producono molteplici versioni dei loro
linguaggi, poiché il problema, e la loro comprensione di esso, evolvono. La
variabilità che ne consegue nelle specifiche, nei linguaggi e nelle
implementazioni introduce dei costi di interoperabilità.
L'estensibilità e il tracciamento della versione
sono strategie per aiutare a gestire l'evoluzione naturale dell'informazione
sul Web e le tecnologie usate per rappresentare quell'informazione. Per
maggiori chiarimenti sul come queste strategie introducano la variabilità e
sul come la variabilità impatti sull'interoperabilità, si veda la
Variabilità nelle Specifiche.
Si veda la questione del TAG XMLVersioning-41, che riguarda le buone prassi nella
progettazione di linguaggi XML estensibili e per trattare il tracciamento
della versione. Si veda inoltre "Web Architecture:
Extensible Languages" [EXTLANG].
Tipicamente esiste un (lungo) periodo di transizione
durante il quale molteplici versioni di un formato, di un protocollo o di
un agente sono in uso simultaneamente.
Buona prassi:
Informazione sulla versione
Una specifica di formato dei
dati DOVREBBE fornire un'informazione sulla versione.
Aneddoto
Nadia e Dirk stanno progettando un formato
di dati XML per codificare i dati dell'industria cinematografica. Essi
provvedono all'estensibilità usando i namespace XML e creando uno
schema che permette l'inclusione, in certi posti, di elementi da
qualsiasi namespace. Quando revisionano il loro formato, Nadia propone
un nuovo attributo lang facoltativo per l'elemento film. Dirk
sente che tale modifica richiede loro di assegnare un nuovo nome al
namespace, che potrebbe richiedere modifiche al software impiegato.
Nadia spiega a Dirk che la loro scelta della strategia di
estensibilità in congiunzione con la loro linea di condotta per il
namespace permettono delle modifiche che non influenzano la conformità
all'identificatore del namespace. Essi hanno scelto questa linea di
condotta per aiutarsi a raggiungere gli obiettivi nel ridurre il costo
della modifica.
Dirk e Nadia hanno scelto una particolare
linea di condotta per la modifca al namespace che permette loro di evitare
di cambiare il nome del namespace ogni volta che fanno dei cambiamenti che
non influenzano la conformità del contenuto e del software impiegati.
Avrebbero potuto scegliere una differente linea di condotta, ad esempio
quella che ogni nuovo elemento o attributo deve appartenere ad un altro
namespace, diverso da quell'originale. Qualunque sia la linea di condotta
scelta, si dovrebbero chiarire agli utenti le aspettative sul formato.
In generale, modificare il nome del namespace
di un elemento cambia completamente il nome dell'elemento. Se "a" e "b"
sono legati a due URI differenti, a:element e b:element
sono distinti come lo sono a:eieio e a:xyzzy. In
parole povere, ciò significa che le applicazioni impiegate dovranno essere
aggiornate per poter riconoscere il nuovo linguaggio; il costo di questo
aggiornamento può essere molto alto.
Ne consegue che esistono intrecci
significativi da considerarsi quando si decide della linea di condotta
nella modifica del namespace. Se un vocabolario non ha alcun punto di
estensibilità (ovvero, se non si consentono elementi o attributi da
namespace esterni o se non si possiede un meccanismo per trattare con i
nomi non riconosciuti per lo stesso namespace), potrebbe essere
assolutamente necessario cambiare il nome del namespace. I linguaggi che
permettono una qualche forma di estensibilità senza richiedere una
modifica del nome del namespace propendono a evolvere più gradualmente.
Buona prassi: Linea di condotta per il namespace
Una specifica di formato XML
DOVREBBE includere l'informazione riguardo le linee di condotta per la
modifica dei namespace XML.
Come esempio di linea di condotta per la
modifica progettata per riflettere la stabilità variabile di un namespace,
si consideri la linea di condotta del W3C per
il namespace per i documenti sulla traccia della Raccomandazione W3C.
La linea di condotta avverte di aspettarsi che il Gruppo di Lavoro
responsabile per il namespace potrebbe modificarlo in qualunque modo fino
ad un certo punto del processo ("Raccomandazione Candidata {Candidate Recommendation}"),
punto in cui il W3C limita il campo delle modifiche possibili al namespace,
in ordine di promuovere implementazioni stabili.
Si noti che dal momento che i nomi di
namespace sono URI, il proprietario di un URI di namespace ha l'autorità
di decidere la politica di modifica del namespace.
I requisiti cambiano nel tempo. Le tecnologie
di successo sono adottate e adattate dai nuovi utenti. I progettisti
possono facilitare il processo di transizione facendo scelte oculate
sull'estensibilità durante la progettazione di una specifica di linguaggio
o di protocollo.
Nel fare queste scelte, i progettisti devono
ponderare gli intrecci fra estensibilità, semplicità e variabilità. Un
linguaggio senza meccanismi di estensibilità potrebbero essere più
semplici e meno variabili, incentivando l'interoperabilità iniziale. n
ogni caso, le modifiche a quel linguaggio tenderanno ad essere più
difficoltose, più complesse e più variabili se possibile, piuttosto che se
la progettazione iniziale avesse fornito tali meccanismi. Ciò potrebbe
diminuire l'interoperabilità sul lungo periodo.
Buona prassi:
Meccanismi di estensibilità
Una specifica DOVREBBE
fornire meccanismi che permettono a qualsiasi parte di creare estensioni.
L'estensibilità introduce la variabilità che
ha un impatto sull'interoperabilità. In ogni caso, i linguaggi che non
possiedono meccanismi di estensibilità potrebbero essere estesi in modi
pensati ad hoc che impattino pure l'interoperabilità. Un criterio
chiave dei meccanismi forniti dai progettisti di linguaggio è che
permettono ai linguaggi estesi di rimanere in conformità alla specifica
originale, incrementando la tendenza all'interoperabilità.
Buona prassi:
Conformità dell'estensibilità
L'estensibilità NON DEVE
interferire con la conformità alla specifica originale.
L'applicazione necessita di determinare la
strategia di estensione il più possibile appropriata per una specifica. Ad
esempio, le applicazioni progettate per operare in ambienti chiusi
potrebbero permettere ai progettisti di specifica di definire una
strategia di tracciamento della versione che sarebbe impraticabile al
livello del Web.
Buona prassi:
Estensioni sconosciute
Una specifica DOVREBBE
specificare il comportamento dell'agente di fronte a estensioni non
riconosciute.
Sono emerse due strategie come particolarmente
utili:
- "Si deve ignorare": L'agente ignora qualsiasi contenuto che non
riconosce.
- "Si deve capire": L'agente tratta la marcatura non riconosciuta come
una condizione d'errore.
Un potente approccio di progettazione per il
linguaggio è consentire sì la forma dell'estensione, ma
distinguere esplicitamente fra loro nella sintassi.
Strategie aggiuntive comprendono richiedere
all'utente ulteriori input e reperire dati automaticamente i dati dai
collegamenti ipertestuali disponibili. Sono possibili anche strategie più
complesse, comprese strategie miste. Per esempio, un linguaggio può
includere meccanismi per soppiantare il comportamento standard. In tal
modo, un formato di dati può specificare la semantica "si deve ignorare",
ma anche consentire estensioni che soppiantano quella semantica alla luce
delle necessità dell'applicazione (per esempio, con semantica "si deve
capire" per una estensione particolare).
L'estensibilità non è libera. Fornire agganci
per l'estensibilità è uno dei molti requisiti da mettersi nel bilancio dei
costi della progettazione di linguaggio. L'esperienza suggerisce che i
benefici a lungo termine di un meccanismo di estensibilità ben progettato
in genere sopravanzano i costi.
Si veda “D.3 Estensibilità
ed Estensioni” in [QA].
Molti formati di dati moderni includono
meccanismi per la composizione. Ad esempio:
- È possibile incorporare commenti testuali in alcuni formati
d'immagine, come JPEG/JFIF. Sebbene questi commenti siano
incorporati nei dati contenuti, non sono intesi ad influenzare la
visualizzazione dell'immagine.
- Esistono formati-contenitore come SOAP che si aspettano ampiamente
del contenuto da molteplici namespace,
ma che forniscono una relazione semantica globale della busta e del
portato del messaggio.
- La semantica dei documenti che combinano RDF che
contengono vocabolari molteplici sono ben definiti.
In principio, queste relazioni si possono
mischiare e annidare in modo arbitrario. Un messaggio SOAP, ad esempio,
può contenere un'immagine SVG che contiene a sua volta un commento RDF che
si riferisce ai termini del vocabolario atti a descrivere l'immagine.
Si noti comunque, che per XML generico non
esiste modello semantico che definisce le interazioni all'interno dei
documenti XML con gli elementi e/o gli attributi da una varietà di
namespace. Ogni applicazione deve definire come i namespace interagiscono
e quale effetto abbia il namespace di un elemento sugli ascendenti,
sui pari grado e sui discendenti dell'elemento.
Si vedano le questioni del TAG
mixedUIXMLNamespace-33 (concernenti il significato di un
documento composito di contenuto nei namespace multipli), xmlFunctions-34 (concernente un solo approccio per gestire la
trasformazione e la componibilità di XML) e RDFinXHTML-35 (concernente l'interpretazione di RDF quando
incorporato in un documento XHTML).
Il Web è un ambiente eterogeneo dove una vasta
gamma di agenti forniscono accesso al contenuto per gli utenti con una vasta
gamma di capacità. È buona prassi per gli autori creare contenuti che
possono il più vasto pubblico possibile, compresi gli utenti di computer con
desktop grafico, dispositivi palmari e telefoni cellulari, utenti con
disabilità i quali potrebbero richiedere sintetizzatori vocali e dispositivi
non ancora immaginati. Inoltre, gli autori non possono predire in alcuni
casi come un agente mostrerà o elaborerà i loro contenuti. L'esperienza
mostra che la separazione del contenuto, della presentazione e
dell'interazione promuove il riutilizzo e l'indipendenza dal dispositivo del
contenuto; ciò consegue dal
principio delle specifiche ortogonali (§5.1).
Questa separazione facilita anche il riutilizzo
di contenuto originario scritto per molteplici contesti distributivi. A volte, esperienze
funzionali per l'utente pensate per qualsiasi contesto distributivo possono
generarsi con l'uso di un processo di adattamento applicato ad una
rappresentazione che non dipende dal meccanismo d'accesso. Per maggiori
informazioni sui principi d'indipendenza dal dispositivo, si veda [DIPRINCIPLES].
Buona prassi: Separazione fra contenuto, presentazione, interazione
Una specifica DOVREBBE
permettere agli autori di separare il contenuto sia dagli aspetti della
presentazione che dell'interazione.
Si noti che quando contenuto, presentazione e
interazione sono seprati dalla progettazione, gli agenti hanno bisogno di
ricombinarli. Esiste uno spettro di ricombinazione, con "client tuttofare"
ad un capo e "server tuttofare" dall'altro.
Esistono vantaggi per ciascun approccio. Per
esempio quando un client (come un telefono cellulare) comunica le capacità
del dispositivo al server (ad esempio, usando CC/PP), il server può
confezionare il contenuto recapitato per adattarsi a quel client. Il server
può, ad esempio, abilitare scaricamenti più veloci aggiustando i
collegamenti per riferirsi a immagini con minore risoluzione, a video più
piccoli o a nessun video del tutto. In modo simile, se il contenuto è stato
scritto in molteplici rami, il server può rimuovere
i rami
inutilizzati prima della consegna. In aggiunta, confezionando il contenuto
per incontrare le caratteristiche di un client di riferimento, il server può
aiutare a ridurre l'elaborazione dal lato client. In ogni caso, rendere il
contenuto specifico in questa maniera riduce l'efficienza del servizio di
cache.
D'altro canto, anche progettare contenuto che
può essere ricombinato dal client tende a far sì che il contenuto sia
applicabile ad una vasta gamma di dispositivi. Questa progettazione inoltre
facilità l'efficienza del servizio di cache e offre agli utenti più
alternative di presentazione. Si possono utilizzare i fogli di stile
dipendenti dal dispositivo per confezionare il contenuto dal lato client per particolari gruppi di dispositivi di riferimento. Per contenuti testuali
con una struttura regolare e ripetitiva, la dimensione combinata del
contenuto di testo più il foglio di stile è tipicamente minore del contenuto
completamente ricombinato; i risparmi incrementano ulteriormente se il foglio di
stile viene riutilizzato da altre pagine.
In pratica viene usata spesso una combinazione
di entrambi gli approcci. La decisione di progetto sul dove dovrebbe
posizionarsi un'applicazione in questo spettro dipende dalla potenza del
client, dalla potenza e dal carico del server e dalla larghezza di banda del
medium che li connette. Se il numero di client possibili è illimitato,
l'applicazione scalerà meglio se un'elaborazione maggiore viene delegata al
client.
Naturalmente, potrebbe non essere desiderabile
raggiungere il pubblico più vasto. I progettisti dovrebbero considerare
tecnologie appropriate per limitare il pubblico, come la crittografia
e il controllo d'accesso (§3.5.2).
Alcuni formati di dati sono progettati per
descrivere la presentazione (inclusi SVG e XSL Formatting Objects {Oggetti
Strutturanti}). I formati di dati come questi dimostrano che fin qui si può solo
separare il contenuto dalla presentazione (o dall'interazione); ad
un certo punto diviene necessario parlare della presentazione. Per il
principio delle specifiche ortogonali (§5.1) questi formati di dati dovrebbero
solo indirizzare a questioni di presentazione.
Si vedano le questioni del TAG formattingProperties-19 (concernenti l'interoperabilità nel caso
di proprietà e nomi di struttura) e contentPresentation-26 (concernente la separazione della
marcatura semantica e di presentazione).
Una caratteristica che definisce il Web è che
consente i riferimenti integrati ad altre risorse attraverso gli URI. La
semplicità di creare collegamenti ipertestuali usando i riferimenti con URI
assoluti (<a href="http://www.example.com/foo">)
e URI relativi (<a href="foo"> and <a
href="foo#anchor">) è responsabile in parte (forse in larga
parte) del successo del Web ipertestuale come lo conosciamo oggi.
Quando una rappresentazione di una singola
risorsa contiene un riferimento ad un'altra risorsa, espressa con un URI che
identifica quell'altra risorsa, questo costituisce un
collegamento fra le due risorse.
Anche metadati aggiuntivi potrebbere formare parte del collegamento (si veda
[XLink10], ad esempio). Nota: In questo
documento, il termine "collegamento" in genere significa "relazione", non
"connessione fisica".
Buona prassi:
Identificazione del collegamento
Una specifica DOVREBBE fornire
i modi per identificare i collegamenti ad altre risorse, comprese le
risorse secondarie
(attraverso gli identificatori di frammento).
I formati che permettono l'utilizzo degli URI
agli autori di contenuto al posto degli identificatori locali promuovo
l'effetto di rete: il valore di questi formati cresce con la dimensione del
Web impiegato.
Buona prassi:
Collegare il Web
Una specifica DOVREBBE
permettere di collegarsi a tutto il Web, non soltanto di collegarsi a
documenti interni.
Buona prassi:
URI
generici
Una specifica DOVREBBE
permettere agli autori di contenuto di utilizzare gli URI senza vincolarli
ad un insieme limitato di schemi di URI.
Ciò che fanno gli agenti con un collegamento
ipertestuale non è vincolato dall'architettura Web e potrebbe dipendere dal
contesto applicativo. Gli utenti dei collegamenti iperetestuali si aspettano
di essere in grado di naviagre fea le rappresentazioni seguendo i
collegamenti.
Buona prassi:
Collegamenti ipertestuali
Un formato di dati DOVREBBE
incorporare i collegamenti ipertestuali se l'ipertesto è il paradigma
atteso d'interfaccia utente.
I formati di dati che non consentono agli autori
di contenuto di creare collegamenti ipertestuali conducono alla creazione di
"nodi terminali" sul Web.
I collegamenti sono comunemente espressi
usando i riferimenti URI (definiti nella sezione 4.2 di [URI]), i quali potrebbero essere combinati con un URI di base per
produrre un URI utilizzabile. La sezione 5.1 di [URI] spiega differenti modi di stabilire un URI di base per una
risorsa e stabilisce una precedenza fra loro. Per esempio, l'URI di base
potrebbe essere u URI per la risorsa o specificata in una rappresentazione
(si vedano gli elementi base forniti da HTML e XML e
l'intestazione 'Content-Location' di HTTP). Si veda inoltre la sezione sui
collegamenti in XML (§4.5.2).
Gli agenti risolvono un riferimento URI prima
di usare l'URI risultante per interagire con un altro agente. I
riferimenti URI aiutano nella gestione del contenuto permettendo agli
autori di contenuto di progettare una rappresentazione in maniera locale,
cioè senza badare che l'identificatore globale possa essere usato in un
secondo momento per riferirsi alla risorsa associata.
Molti formati di dati sono
basati su XML, che equivale a dire che essi si
conformano alle regole di sintassi definite nella specifica XML [XML10] o [XML11]. Questa sezione tratta questioni che sono specifiche di
tali formati. Chiunque cerchi una guida in questo campo si affretti a
consultare le "Linee Guida Per l'Utilizzo di XML nei Protocolli IETF" [IETFXML], che contiene una discussione approfondita sulle
considerazioni che decidono se XML debba essere utilizzato o no, come pure
le
linee guida specifiche sul come debba essere utilizzato. Anche se è diretta
alle applicazioni Internet con specifico riferimento ai protocolli, la
discussione è applicabile in genere anche agli scenari Web.
La discussione qui dovrebbe essere vista come
sussidiaria al contenuto di [IETFXML]. Si prenda a riferimento anche "Linee Guida per
l'Accessibilità in XML" [XAG] per un aiuto nella progettazioni di formati XML che
abbassino le barriere per l'accessibilità sul Web a favore delle persone con
disabilità.
XML definisce formati di dati testuali che
sono per natura adatti a descrivere gli oggetti di dati che siano
gerarchici ed elaborati in una sequenza prescelta. È largamente, ma non
universalmente, applicabile per formati di dati; un formato di audio o
video, ad esempio, non è probabile che sia ben adatto all'espressione in
XML. Vincoli della progettazione che suggerirebbero l'utilizzo di XML
comprendono:
- Requisito di una struttura gerarchica.
- Necessità di una vasta gamma di strumenti su una varietà di
piattaforme.
- Necessità di dati che sopravvivono alle applicazioni che adesso le
processano.
- Capacità di supportare l'internazionalizzazione in un modo
auto-descrittivo che non tenda a far confusione sulle opzioni di
codifica.
- Riconoscimento precoce degli errori di codifica con nessuna
richiesta di "aggirare" tali errori.
- Un'alta proporzione di contenuto testuale intelligibile agli umani.
- Composizione potenziale dei formati di dati con altri formati
codificati in XML.
- Desiderio di dati facilmente interpretabili sia dagli esseri umani
che dalle macchine.
- Desiderio di vocabolari che possono essere inventati in una maniera
distribuita e flessibilmente combinata.
I meccanismi sofisticati di collegamento sono
stati inventati per i formati XML. XPointer permette ai collegamenti di
indirizzare il contenuto che non possiede un'ancora esplicita, con un
nome. [XLink] è una specifica appropriata per rappresentare i
collegamenti nell'ipertesto (§4.4) delle applicazioni XML. XLink permette ai
collegamenti di avere molteplici fini e di essere espresso sia in linea
che immagazzinati in "basi di collegamento" esterne a tutte o alcune
risorse identificate dai collegamenti che esso contiene.
I progettisti di formati basati su XML
potrebbero considerare di utilizzare XLink e, per definire la sintassi
dell'identificatore di frammento, usando l'area di lavoro di XPointer e
gli Schemi element() di XPointer.
XLink non è la sola progettazione del fare
collegamenti che sia stata proposta per XML, né è universalmente accettata
come una buona progettazione. Si veda anche la questione del TAG xlinkScope-23.
Il proposito di un namespace XML (definito in
[XMLNS]) è permettere l'impiego dei vocabolari XML (nei quali sono
definiti i nomi di elementi e di attributo) in un ambiente globale e
ridurre il rischio delle collisioni dei nomi in un dato documento quando
vengono combinati i vocabolari. Ad esempio, le specifiche MathML e SVG
definiscono entrambe l'elemento set. Sebbene i dati XML da
differenti formati come MathML e SVG possono combinarsi in un singolo
documento, in questo caso potrebbe esserci ambiguità riguardo a quale
elemento set si intenda. I namespace XML riducono il rischio
delle collisioni dei nomi avvantaggiandosi dei sistemi esistenti per
allocare in modo globale gli ambiti dei nomi: il sistema URI (si veda
anche la sezione sull'allocazione di URI (§2.2.2)). Quando si usano i namespace XML,
ogni nome locale in un vocabolario XML è accoppiato con un URI (chiamato
l'URI del namespace) per distinguere il nome locale dai nomi locali in
altri vocabolari.
L'utilizzo degli URI conferisce benefici
aggiuntivi. Primo, ogni coppia di URI/nome locale si può far corrispondere
a un altro URI, dando la base ai termini del vocabolario nel Web. Questi termini
potrebbero essere risorse importanti e in tal modo è appropriato essere in
grado di associare gli URI con loro.
[RDFXML] usa una concatenazione semplice dell'URI di namespace e
del nome locale per creare un URI per il termine identificato. Altre
corrispondenze tendono ad essere più adattabili ai namespace gerarchici; si veda la
relativa questione del TAG abstractComponentRefs-37.
I progettisti di formati di dati basati su XML
che dichiarano i namespace in
questo modo rendono possibile riutilizzare quei formati di dati e
combinarli in maniere insolite non ancora
immaginate. Il fallimento nel dichiarare i namespace rende tale riutilizzo
più arduo, perfino non pratico in alcuni casi.
Buona prassi:
Adozione del namespace
Una specifica che stabilisce
un vocabolario XML DOVREBBE porre in un namespace tutti i nomi di
elemento e i nomi di attributo globale .
Gli attributi sono sempre contestualizzati
dall'elemento nel quale compaiono. Un attributo che è "globale", è questo,
uno che potrebbe apparire in modo sensato in elementi di vari tipi,
inclusi gli elementi in altri namespace, dovrebbe essere posto in modo
esplicito in un namespace. Gli attributi locali, quelli associati con un
solo tipo di elemento particolare, necessitano di non essere inclusi in un
namespace dal momento che il loro significato sarà sempre chiarito dal
contesto fornito da quell'elemento.
L'attributo type dal namespace
del
XML Schema Instance del W3C "http://www.w3.org/2001/XMLSchema-instance" ([XMLSCHEMA], sezione 4.3.2) è un esempio di un attributo globale.
Può essere usato dagli autori di tutti i vocabolari per fare
un'affermazione sui dati d'esempio riguardo al tipo dell'elemento nel
quale appare. Come un attributo globale, deve essere sempre qualificato.
L'attributo frame di una tabella HTML è un esempio di un
attributo locale. Non esiste alcun valore che rimpiazzi quell'attributo in
un namespace dal momento che l'attributo non tende ad essere utile in un
elemento diverso dalla tabella HTML.
Le applicazioni che si appoggiano
all'elaborazione del DTD devono imporre vincoli aggiuntivi sull'uso dei
namespace. I DTD compiono una convalidazione basata sulla forma lessicale dei
nomi dell'elemento e dell'attributo nel documento. Ciò rende sintatticamente
significativi i prefissi in modi che non sono previsionati [XMLNS].
Aneddoto
Nadia riceve dei dati di rappresentazione
da "weather.example.com" in
un formato di dati non familiare. Ella conosce abbastanza di XML per
riconoscere a quale namespace di XML appartengono gli elementi. Dal
momento che il URI "http://weather.example.com/2003/format", ella
chiede al suo browser di reperire una rappresentazione della risorsa
identificata. Ella ottiene dati utili che le permettono di imparare
altre cose riguardo al formato dei dati. Il browser di Nadia potrebbe
anche compiere alcune operazioni in modo automatico (cioè, non seguito
da un ispettore umano)
una volta forniti i dati che si devono ottimizzare per gli agenti
software. Ad esempio, il suo browser potrebbe, al posto di Nadia,
scaricare agenti supplementari per elaborare e presentare il formato.
Un altro beneficio nell'usare gli URI per
costruire i namespace XML è che l'URI del namespace può essere utilizzato
per identificare una risorsa informativa che contiene informazioni utili,
trattabili da macchine e/o da esseri umani, riguardo i termini del
namespace. Questo tipo di risorsa informativa è chiamata un
documento di namespace. Quando un
proprietario di URI del namespace fornisce un documento di namespace, è
autoritativo per il namespace.
Esistono molte ragioni per fornire un
documento di namespace. Una persona potrebbe volere:
- capire il fine del namespace,
- imparare come usare il vocabolario di marcatura nel namespace,
- trovare chi lo controlla e le linee di condotta associate,
- richiedere l'autorità di accedere agli schemi o a materiale
collaterale che lo riguarda, oppure
- riportare un malfunzionamento o una situazione che potrebbe essere
considerata un errore in alcuni materiali collaterali.
Un elaboratore potrebbe volere:
- reperire uno schema, per la convalidazione,
- reperire un foglio di stile, per la presentazione, oppure
- reperire le ontologie, per fare le deduzioni.
In generale, non esiste una prassi
prestabilita migliore in assoluto per creare le rappresentazioni di un
documento di namespace; le aspettative dell'applicazione influenzeranno
per cosa i formati di dati o formati sono utilizzati. Inoltre le
aspettative dell'applicazione influenzeranno se la relativa informazione
apparirà direttamente in una rappresentazione o se si farà ad essa un
riferimento da questa.
Buona prassi:
Documenti del namespace
Il proprietario di un nome di
namespace XML DOVREBBE rendere disponibile del materiale predisposto per
esser letto da persone e materiale ottimizzato per gli agenti software
in modo da andare incontro alle necessità di quelli che utilizzeranno il
vocabolario del namespace.
Ad esempio, quelli che seguono sono esempi di
formati di dati per documenti di namespace: [OWL10], [RDDL], [XMLSCHEMA], e [XHTML11]. Ognuno di questi formati va incontro a differenti
requisiti sopradescritti per soddisfare le necessità di un agente
chevoglia magiore informazione riguardo al namespace. Si notino, comunque,
le questioni relative a identificatori di frammento e negoziazione del contenuto (§3.2.2)
se viene usata la negoziazione del contenuto.
Si vedano le questioni del TAG
namespaceDocument-8 (concernente le caratteristiche desiderate
dei documenti di namepsace) e abstractComponentRefs-37 (concernente l'uso degli identificatori
di frammento con i nomi del namespace per identificare componenti astratti).
La sezione 3 di "I Namespace in XML" [XMLNS] fornisce un costrutto sintattico conosciuto come un QName
per l'espressione cmpatta dei nomi qualificai nei documenti XML. Un nome
qualificato è una coppia consistente di un URI, che dà il nome a un
namespace, e un nome locale posto all'interno di quel namespace. "I
namespace in XML" fornisce elementi e attributi per l'uso dei QName come
nomi per XML.
Altre specifiche, a partire da [XSLT10], hanno assunto l'idea di usare i QName in contesti
diversi dai nomi di elemento e di attirbuto, ad esempio nei valori di
attributo e nel contenuto di elemento. In ogni caso, gli elaboratori
generici di XML non possono riconoscere in modo affidabile i QNames come
tali quando vengono utilizzati nei valori di attributo e nel contenuto di
elemento; ad esempio, la sintassi dei QName si sovrappone con quella degli
URI. L'esperienza ha messo in luce anche altre limitazioni dei QName, come
la perdita dei legami con il namespace dopo la
canonizzazione XML.
Vincolo: QName Indistinguibili dagli
URI
Non consentire né i QName
né gli URI nei valori di attributo o nel contenuto di elemento quando
essi sono indistinguibili.
Per maggiori informazioni, si veda la
conclusione del TAG "Usare i QNames
come Identificatori nel Contenuto".
Poiché i QName sono compatti, alcuni
progettisti di specifica hanno adottato la medesima sintassi come mezzo
per identificare le risorse. Sebbene sia conveniente come notazione
abbreviata, questo impiego ha un costo. Non esiste un solo modo accettato
per ocnveritre un QName in un URI o viceversa. Sebbene i QName siano
convenienti, essi non sostituiscono gli URI come sistema di
identificazione sul Web. L'uso dei QName per identificare le risorse Web
senza fornire una corrispondenza con gli URI è inconsistente con l'architettura
Web.
Buona prassi:
Dare corrispondenze ai QName
Un specifica nella quale i
QName servano come identificatori di risorsa DEVE fornire una
corrispondenza con gli URI.
Si veda
I namespace in XML (§4.5.3) per esempi di alcune strategie nel
creare corrispondenze.
Si vedano inoltre le questioni del TAG rdfmsQnameUriMapping-6 (concernente il creare corrispondenze dai QName
agli URI), qnameAsId-18 (concernente l'uso dei QName come identificatori nel
contenuto di XML) e abstractComponentRefs-37 (concernente l'uso degli identificatori
di frammento con i nomi di namespace per identificare componenti astratti).
Si consideri il seguente frammento di XML: <section
name="foo">. L'elemento section possiede ciò a
cui la Raccomandazione XML si riferisce come l'ID foo (cioè, "foo"
non deve apparire nel documento XML circostante più di una
volta)? Non si può rispondere a questa domanda esaminando l'elemento e i
suoi attributi da soli. In XML, la qualità di "essere un ID" è asociata
con il tipo di un attributo, non con il suo nome. Trovare gli ID in un
documento richiede un'elaborazione supplementare.
- Processare il documento con un elaboratore che riconosce le
dichiarazioni dell'elenco degli attributi nel DTD (nel sottoinsieme
esterno o interno) potrebbe rivelare una dichiarazione che identifica
l'attributo
name come un
ID. Nota: Questa elaborazione non è necessariamente
parte di una validazione. Un elaboratore non fa la validazione, ma è a
conoscenza del DTD, può riconoscere gli ID.
- Processare il documento con uno schema XML del W3C potrebbe rivelare
una dichiarazione di elemento che identifica l'attributo
name
come un ID dello Schema XML del W3C.
- In pratica, processando il documento con il linguaggio di un altro
schema, come RELAX NG [RELAXNG], potrebbe rivelare che gli attributi vengono
dichiarati ID nel significato dello Schema XML. Molte specifiche recenti
iniziano ad elaborare XML a livello dell'Infoset [INFOSET] e non specificano in modo normativo come venga
costruito un Infoset. Per quelle specifiche, ogni elaborazione che
stabilisca il tipo di ID nell'Infoset (e lo Schema Post di Convalidazione
Infoset {Post Schema Validation Infoset} (PSVI)
definito in [XMLSCHEMA]) potrebbe identificare in maniera utile gli
attributi di tipo ID.
- In pratica, le applicazioni potrebbero avere mezzi indipendenti
(come quelli definiti nella specifica XPointer, [XPTRFR] sezione 3.2) per localizzare gli identificatori all'interno di
un documento.
Per complicare ulteriormente la faccenda, i
DTD stabiliscono il tipo di ID nell'Infoset laddove lo Schema
XML del W3C produce un PSVI, ma non modifica l'Infoset originale. Ciò
lascia aperta la possibilità che un elaboratore potrebbe guardare solo
nell'Infoset e conseguentemente fallirebbe nel riconoscere gli ID
assegnati da schema.
Si veda la questione del TAG
xmlIDSemantics-32 per informazioni aggiuntive sui retroscena e [XML-ID] per una soluzione in sviluppo.
La RFC 3023 definisce i tipi di media per
Internet "application/xml" e "text/xml",
e descrive una convenzione per mezzo della quale i formati di dati basati su XML
utilizzano i tipi di media per Internet con un suffisso "+xml", ad esempio "image/svg+xml".
Esistono due problemi associati con i tipi di
media “text”: Primo, per i dati identificati come "text/*", agli
intermediari Web viene consentito di "transcodificare", cioè, convertire
una codifica di carattere in un'altra. Transcodificare potrebbe rendere
falsa l'auto-descrizione oppure potrebbe causare il fatto che il documento
non sia ben-formato.
Buona prassi: XML e "text/*"
In generale, colui che
fornisce la rappresentazione NON DOVREBBE assegnare i tipi di media per
Internet che cominciano con "text/" a rappresentazioni
XML.
Secondo, le rappresentazioni i cui tipi di
media per Internet cominciano con "text/" sono obbligatorie, a meno che
sia specificato il parametro charset, da considerarsi come
codificato in US-ASCII. Dal momento che la sintassi di XML è progettata
per rendere i documenti auto-descrittivi, è buona prassi omettere il
parametro charset, and dacchè XML molto spesso non è
codificato in US-ASCII, l'utilizzo dei tipi di media per Internet "text/"
in effetti preclude questa buona prassi.
Buona prassi: XML e codifiche di carattere
In generale, colui che
fornisce la rappresentazione NON DOVREBBE specificare la codifica di
carattere per i dati XML nelle intestazioni del protocollo dal momento
che i dati sono auto-descrittivi.
La sezione su
tipi di media e semantica dell'identificatore di frammento (§3.2.1) discute
l'interpretazione degli identificatori di frammento. I progettisti di una
specifica di formato di dati basato su XML dovrebbero definire la
semantica degli identificatori di frammento in quel formato. Il Framework
di XPointer [XPTRFR] fornisce un punto di partenza interoperabile.
Quando il tipo di media assegnato ai dati
della rappresentazione è "application/xml", non esiste alcuna semantica
definita per gli identificatori di frammento, e gli autori non dovrebbero
fare uso di identificatori di frammento in tali dati. Lo stesso è vero se
il tipo di media assegnato ha il suffisso "+xml" (definito "Tipi di Media
per XML" [RFC3023]), e la specifica del formato di dati non specifica la
semantica dell'identificatore di frammento. In breve, sapendo solo che il
contenuto è XML non fornisce informazioni sulla semantica
dell'identificatore di frammento.
Molte persone presuppongono che
l'identificatore di frammento #abc,
quando si riferisce a dati XML, identifica l'elemento nel documento con
l'ID "abc". In ogni caso, non esiste alcun sostegno normativo a questa
supposizione. Ci si aspetta una revisione della RFC 3023 che vada in
questa direzione.
Si veda la questione del TAG fragmentInXML-28.
4.6. Direzioni Future per i Formati di Dati
I formati di dati abilitano la creazione di
nuove applicazioni per fare uso dell'infrastruttura dello spazio
informativo. Il Web Semantico è una di tali applicazioni, costruita in cima
alla RDF [RDFXML]. Questo documento non discute del Web Semantico in
dettaglio; il TAG si aspetta che i volumi futuri di questo documento lo
faranno. Si veda la relativa questione del TAG httpRange-14.
Un numero di principi generali di architettura si
applicano a tutte e tre le basi dell'architettura Web.
L'identificazione, l'interazione e la
rappresentazione sono concetti ortogonali, il che significa che le
tecnologie utilizzate per l'identificazione, l'interazione e la
rappresentazione potrebbero evolvere in maniera indipendente. Per esempio:
- Le risorse sono identificate con gli URI. Gli URI possono essere
pubblicati senza costruire alcuna rappresentazione della risorsa o senza
determinare se sia disponibile una qualsiasi rappresentazione.
- Una sintassi generica di permette agli agenti di funzionare in molti
casi senza conoscere le specifiche degli schemi di URI.
- In molti casi si potrebbe modificare la rappresentazione di una risorsa
senza intralciare i riferimenti esistenti alla risorsa (ad esempio,
usando la negoziazione del contenuto).
Quando due specifiche sono ortogonali, si
potrebbe cambiarne una senza richiedere modifiche all'altra, perfino se una
avesse delle dipendenze con l'altra. Ad esempio, sebbene la specifica HTTP
dipenda dalla specifica URI, le due strade evolvono in maniera indipendente.
Questa ortogonalità incrementa la flessibilità e la robustezza del Web. Ad
esempio, ci si potrebbe riferire con un URI ad un'immagine senza conoscere
nulla riguardo al formato scelto per rappresentare l'immagine. Questo ha
facilitato l'introduzione dei formati di immagine come PNG e SVG senza
interrompere
i riferimenti esistenti alle risorse dell'immagine.
Principio: Ortogonalità
Le astrazioni ortogonali
beneficiano delle specifiche ortogonali.
L'esperienza dimostra che sorgono problemi dove
i concetti ortogonali occorrono in una singola specifica. Si consideri, ad
esempio, la specifica HTML la quale include la specifica ortogonale x-www-form-urlencoded.
Gli sviluppatori software (ad esempio, delle applicazioni [CGI]) potrebbero trovare in minor tempo la specifica se essa
fosse pubblicata separatamente e poi citata dalle specifiche HTTP, URI e
HTML.
Sorgono problemi anche quando le specifiche
tentano di modificare le astrazioni ortogonali descritte altrove. Una
versione storica della specifica HTML aggiunse un valore "Refresh"
all'attributo http-equiv dell'elemento meta.
Fu definito essere equivalente all'intestazione HTTP con lo stesso nome.
Gli autori della specifica HTTP ultimamente hanno deciso di non fornire
questa intestazione e ciò ha messo in modo imbarazzante le due specifiche in
disaccordo l'una con l'altra. Il Gruppo di Lavoro del W3C alla fine
ha rimosso il valore "Refresh".
Una specifica dovrebbe indicare chiaramente
quali caratteristiche si sovrappongono a quelle governate da un'altra
specifica.
L'informazione nel Web e le tecnologie usate per
rappresentare quell'informazione cambiano nel tempo. L'estensibilità è la
proprietà di una tecnologia che promuove l'evoluzione senza sacrificare
l'interoperabilità. Alcuni esempi di tecnologie di successo progettate per
consentire la modifica minimizzando al contempo l'interruzione includono:
- il fatto che gli schemi di URI sono specificati in modo ortogonale;
- l'utilizzo di un insieme aperto dei tipi di media per Internet nella
posta e in HTTP per specificare l'interpretazione del documento;
- la separazione della grammatica generica XML e l'insieme aperto dei
namespace XML per i nomi di elemento e attributo;
- i modelli di estensibilitàextensibility nei Fogli di Stile a Cascata {Cascading Style Sheets} (CSS), XSLT 1.0
e
SOAP;
- gli agenti utenti di tipo plug-in.
Un esempio di meccanismo estensivo non di
successo sono le estensioni obbligatorie di HTTP [HTTPEXT]. La comunità ha cercato meccanismi per estendere HTTP,
ma in apparenza i costi della proposta dell'estensione obbligatoria
(notevole per complessità) ha sopravanzato i benefici e in tal modo ne
ha impedito l'adozione..
Di seguito discutiamo la proprietà
dell'"estensibilità", esposta dagli URI, da alcuni formati di dati e da
alcuni protocolli (attraverso l'incorporazione di nuovi messaggi).
Linguaggio di sottoinsieme: un linguaggio è
un sottoinsieme (o "profilo") di un secondo linguaggio se ogni documento nel
primo linguaggio è un documento valido anche nel secondo linguaggio e ha la
stessa interpretazione nel secondo linguaggio.
Linguaggio esteso: se un linguaggio è un
sottoinsieme di un altro, quest'ultimo soprainsieme è chiamato un linguaggio
esteso; la differenza tra i linguaggio è chiamata l'estensione. Chiaramente,
estendere un linguaggio per l'interoperabilità è meglio che creare un
linguaggio incompatibile.
Idealmente, molte istanze di un linguaggio di
soprainsieme possono essere elaborate in maniera sicura e proficua come se queste esistano nel linguaggio di sottoinsieme. I linguaggi che
possono evolvere in questa maniera, permettendo alle applicazioni di fornire
nuova informazione quando necessario pur continuando a interoperare con le
applicazioni che capiscono solo un sottoinsieme del linguaggio in uso, si
dice che sono "estensibili". I progettisti di linguaggio possono facilitare
l'estensibilità definendo il comportamento predefinito delle estensioni
sconosciute — ad esempio, che esse siano ignorate (in qualche modo
predefinito) o dovrebbero essere considerate errori.
Ad esempio, nel Web fin dal principio, gli
agenti HTML seguivano la convenzione di ignorare i tag sconosciuti. Questa
scelta lasciava spazio all'innovazione (cioè, elementi non standard) e
incoraggiava l'impiego di HTML. In ogni caso, sorsero anche problemi di interoperabilità. In questo tipo di ambiente, esiste un'inevitabile
tensione fra l'interoperabilità nel breve periodo e il desiderio di
estensibilità. L'esperienza ci mostra che le progettazioni che raggiungono
il giusto bilanciamento fra permettere il cambiamento e preservare
l'interoperabilità tendono di più a far prosperare e meno ad intralciare la
comunità Web. Le specifiche ortogonali (§5.1) aiutano a ridurre il rischio di
intralcio.
Per una discussione ulteriore, si veda la
sezione sul tracciamento della versione e l'estensibilità (§4.2). Si veda
anche la questione del TAG xmlProfiles-29 e HTML Dialects.
Nei sistemi informativi di rete gli errori si
verificano.
Una condizione di errore può essere ben caratterizzata (cioè, gli errori
di non corretta formazione oppure gli errori del client 4xx in HTTP) o
sorgere in maniera inopinata. La
correzione dell'errore significa che un
agente ripara una condizione in modo tale che all'interno del sistema, è
come se l'errore non si fosse mai verificato. Un esempio di correzione
d'errore coinvolge la ritrasmissione dei dati in risposta ad una caduta
temporanea della rete. Il recupero dell'errore significa che un
agente non ripara una condizione d'errore, ma continua ad elaborare
puntando sul fatto che si è verificato l'errore.
Gli agenti correggono di frequente gli
errori senza che l'utente ne sia conscio, risparmiando agli utenti i
dettagli delle complesse comunicazioni di rete. D'altro, è importante che gli
agenti recuperino l'errore in un modo che sia evidente per gli
utenti, dal momento che gli agenti si stanno comportando come se fossero gli
utenti.
Principio:
Recupero
dell'errore
Gli agenti che recuperano
l'errore operando una scelta senza il consenso dell'utente non si stanno
comportando come se fossero l'utente.
A un agente non viene richiesto di interrompere
l'utente (cioè, facendo uscir fuori una finestra di conferma) per ottenere
il consenso. L'utente potrebbe acconsentire attraverso le opzioni
pre-selezionate di configurazione, modi oppure interruttori
selezionabili dell'interfaccia utente, con un'opera di rapporto appropriata
all'utente quando l'agente scova un errore. Gli sviluppatori di agenti non
dovrebbero ignorare le questioni di usabilità quando progettano il
comportamento per il recupero dell'errore.
Per promuovere l'interoperabilità, i progettisti
di specifica dovrebbero identificare le condizioni prevedibili di errore.
L'esperienza ha portato a formulare le seguenti osservazioni sugli approcci
alla gestione dell'errore.
- I progettisti di protocollo dovrebbero fornire sufficiente
informazione sulla condizione d'errore in modo tale che un agente possa
localizzare
la condizione dell'errore. Per esempio, un codice di status 404 di HTTP
(non trovato) è utile perché consente agli agenti utente di presentare
la relativa informazione agli utenti, abilitandoli a contattare il
fornitore della rappresentazione in caso di problemi.
- L'esperienza con il costo della costruzione di un agente utente nel
trattare con diverse forme di contenuti HTML malformati ha convinto i
progettisti della specifica XML a richiedere che gli agenti falliscano nel
momento in cui incontrino contenuto malformato. Poiché gli utenti tendono
a non tollerare tali fallimenti, questa scelta ha messo pressione su tutte
le parti a rispettare i vincoli di XML, per il beneficio di tutti.
- Un agente che incontra del contenuto non riconosciuto potrebbe
trattarlo in un certo numero di modi, incluso considerarlo un errore; si
veda anche la sezione sulla
estensibilità e il tracciamento della versione (§4.2).
- Il comportamento dell'errore che è appropriato per una persona
potrebbe non esserlo per un software. Le persone sono in grado di
esercitare un giudizio in modi che sono in genere preclusi agli
applicativi. Una risposta informale d'errore potrebbe esser sufficiente
per una persona, ma non per un elaboratore.
Si veda la questione del TAG contentTypeOverride-24, che concerne la fonte dei metadati
autoritativi.
Il Web segue la tradizione Internet per cui le
sue interfacce importanti sono definite in termini di protocolli,
specificando la sintassi, la semantica e i conseguenti vincoli dei messaggi
scambiati. I protocolli progettati per essere elastici di fronte ad
ambienti che variano in maniera ampia hanno aiutato il Web a scalare e ha facilitato
la comunicazione attraverso connessioni multiple affidabili. Le tradizionali
interfacce di programmazione d'applicativo {application programming interfaces} (le API)
non sempre prendono in considerazione questi vincoli, né dovrebbero essere
richiesto loro. Un effetto della progettazione basata sul protocollo è che
la tecnologia condivisa fra gli agenti spesso dura più a lungo degli agenti
stessi.
È cosa comune per i programmatori lavorare con
il Web per scrivere codice che genera e interpreta questi messaggi in mdoo
diretto. È meno comune, ma non inusuale, per gli utenti finali avere
un'esposizione diretta di quei messaggi. Spesso è preferibile fornire agli
utenti l'accesso ai dettagli del formato e del protocollo: permettendo loro
di "vedere la fonte", con questo mezzo essi possono fare esperienza
sulle
lavorazioni del sistema sottostante.
Questo documento è stato scritto dal Gruppo
Tecnico per l'Architettura {Technical
Architecture Group} del W3C che include i seguenti partecipanti: Tim Berners-Lee
(co-Presidente, W3C), Tim Bray (Antarctica Systems), Dan Connolly (W3C), Paul
Cotton (Microsoft Corporation), Roy Fielding (Day Software), Mario Jeckle
(Daimler Chrysler), Chris Lilley (W3C), Noah Mendelsohn (IBM), David Orchard
(BEA Systems), Norman Walsh (Sun Microsystems) e Stuart Williams (co-Presidente,
Hewlett-Packard).
Il TAG ha apprezzato i molti contributi della sua
lista pubblica di distribuzione, www-tag@w3.org (archivio),
la quale è stata d'aiuto nel migliorare questo documento.
In aggiunta, si riconoscono con gratitudine i
contributi di David Booth, Erik
Bruchez, Kendall Clark, Karl Dubost, Bob DuCharme, Martin Duerst, Olivier
Fehr, Al Gilman, Tim Goodwin, Elliotte Rusty Harold, Tony Hammond, Sandro
Hawke, Ryan Hayes, Dominique Hazaël-Massieux, Masayasu Ishikawa, David M.
Karr, Graham Klyne, Jacek Kopecky, Ken Laskey, Susan Lesch, Håkon Wium Lie,
Frank Manola, Mark Nottingham, Bijan Parsia, Peter F. Patel-Schneider, David
Pawson, Michael Sperberg-McQueen, Patrick Stickler e Yuxiao Zhao.